
Tested Claude AI LLM Models' Effort Levels - Low To Max: How Claude Opus 4.7 differs
Opus 4.7 [1m], Opus 4.6 [1m], Opus 4.5, and Sonnet 4.6 benchmark tested on 10 prompts at every effort level from low to max

Claude Code now exposes a reasoning_effort knob with five public rungs: low, medium, high, xhigh, max. The pitch is simple. Higher effort means more thinking, which means better answers on hard problems.
The unasked question is what that knob actually costs, in tokens and dollars, and whether the same crank behaves the same way across different models. I spent an afternoon of subscription quota finding out. Read on if you want to understand how Claude Opus and Sonnet models’ effort levels impact your token usage, costs and performance.
Four models, every effort rung, 10 canonical prompts per rung, 220 headless claude -p subprocesses. Total spend: around $18. The short version is that “higher effort = more money” is almost right but misses the more interesting story underneath. The four models have qualitatively different personalities. The knob amplifies those personalities in four different directions, and Opus 4.7 is so different from the other three that it is better thought of as a new product class than a new model version.
The rest of this post is the long version: every number, twelve cross-model charts, and four confounds that mislead careless readers of the raw data.

Background
This follows on from I Ran Opus 4.6 and 4.7 on the Same 10 Prompts at 1M Context, which covered what the effort knob looks like at one rung across two models. This post runs the other axis: four models, every rung, same 10 prompts.
Both rely on my session-metrics plugin, first covered in My Claude Code Plugin Marketplace Is Now Public and used again in I Ran Two 5-Hour Opus 4.7 Blocks in One Day. The short version: session-metrics parses Claude Code’s own JSONL transcripts and rebuilds the exact cost breakdown from token counts and the published price list. The new benchmark-effort subcommand used here spawns an effort-rung ladder in one shot. No API key needed; it rides on your existing subscription quota.
TL;DR
Claude Max Plan $100 used. Tests below were done within Claude Code CLI 2.1.117. Note from Anthropic post-mortem on Claude Code quality degradation issues, they mentioned Claude Code 2.1.116+ have it fixed.
Effort is an output-token dial, not an input dial. Every session paid ~6 input tokens per prompt. Cost lives in the output column, which includes thinking blocks and tool-use JSON. The knob slides how much the model writes, not how much you type.
Three behavioural regimes, not four models. Opus 4.6, 4.5, and Sonnet 4.6 already think on 90 to 100 percent of turns at
loweffort. Opus 4.7 is the outlier: reserves thinking for hard turns atlow(18 percent) and only ramps to 93 percent atmax.Sonnet 4.6 is the generalist agent. Always reaches for tools (9 calls across 18 to 19 turns at every rung), thinks on every turn, produces the most output tokens per run, yet costs less than Opus at the same rung because its list price is 60 percent of Opus’s. Measured in tokens per dollar, it is 2 to 5x more efficient than any Opus variant.
Cache warmth is a first-order confound. The same model at the same effort level can swing up to 1.88x depending on whether the 1-hour prompt cache was warm on turn 1. Opus 4.7 [1M]
xhighcosts $1.12 warm vs $1.78 cold; Sonnet 4.6mediumcosts $0.78 warm vs $1.46 cold. Any sub-1.3x cost ratio in this bundle is inside the noise floor.The
maxrung is a different product. On Opus 4.7,maxtriggers thinking on 93 percent of turns and produces 6.5x more output tokens thanlow. On Opus 4.5 the same dial produces only 2.1x more output: caps out earlier.IFEval is noise at N = 9. Nine compliance checks per side means one prompt flipping moves the pass rate by 11.1 percentage points. Every McNemar p-value sits at 0.25 to 0.5. The evidence cannot rule out a coin flip.
Key terms (short glossary)
Skim whatever you already know.
Token. Billing unit. Roughly 4 English characters per token; a short prompt is ~100 tokens, a long article ~5,000.
Context window. How much Claude can see at once. The
[1m]suffix means 1 million tokens. Opus 4.7/4.6 sides use[1m]; Opus 4.5 and Sonnet 4.6 use the standard tier.Effort level. A Claude Code setting (
/effort low | medium | high | xhigh | max) that controls how hard the model thinks before answering. Higher effort usually means more hidden thinking tokens and longer answers, at a higher bill.Turn. One round-trip exchange. A user message plus model reply is one turn. Tool calls and their replies add separate turns.
Thinking block. Claude’s hidden reasoning step, billed at the output rate even though you never see it.
Tool call. When the model asks Claude Code to run a command (
Bash,Read,Glob, etc.) before answering.Cache read / cache write. Once Claude has processed your system prompt, Claude Code stores it in a short-lived cache. Follow-up turns pay a cheap cache-read fee instead of re-processing. Cache writes cost more up front but save money on every later turn.
1-hour TTL vs 5-minute TTL. Claude Code can write cache entries that live 5 minutes or 1 hour. The 1-hour tier costs 60 percent more per write token but keeps savings flowing over longer sessions. Claude Code’s headless mode uses the 1-hour tier 100 percent of the time for Claude Max plan subscriptions.
IFEval. A public benchmark (Zhou et al. 2023) that programmatically grades whether a model followed a specific instruction literally.
pp (percentage points). The arithmetic difference between two percentages. 100 percent minus 89 percent is 11 percentage points, not “11 percent better” (which would be a ratio).
Canonical suite. A fixed set of 10 test prompts that ship with
session-metrics, covering the content shapes Anthropic’s tokenizer write-up measured.McNemar p-value. A statistical test for paired yes/no outcomes. A p-value under 0.05 means the difference is unlikely to be random. Every pair in this bundle sits at 0.25 to 0.5, which means “cannot tell if the difference is real or a coin flip”.
What actually ran
Four benchmark bundles, one per model. Every bundle runs the model against itself at different effort rungs using session-metrics compare-run. That matters: the ratios inside a single bundle reflect effort-level behaviour plus run-to-run variance, not model-vs-model. The cross-model story comes from aligning the four bundles at matched effort rungs.
Command log
# big-compare-1 - Opus 4.7 with the 1M-token context variant
session-metrics compare-run 'claude-opus-4-7[1m]' 'claude-opus-4-7[1m]' --compare-run-effort low medium
session-metrics compare-run 'claude-opus-4-7[1m]' 'claude-opus-4-7[1m]' --compare-run-effort high xhigh
session-metrics compare-run 'claude-opus-4-7[1m]' 'claude-opus-4-7[1m]' --compare-run-effort xhigh max
# big-compare-2 - Opus 4.6 [1m]
session-metrics compare-run 'claude-opus-4-6[1m]' 'claude-opus-4-6[1m]' --compare-run-effort low medium
session-metrics compare-run 'claude-opus-4-6[1m]' 'claude-opus-4-6[1m]' --compare-run-effort high max
# big-compare-3 - Opus 4.5 (standard context)
session-metrics compare-run 'claude-opus-4-5' 'claude-opus-4-5' --compare-run-effort low medium
session-metrics compare-run 'claude-opus-4-5' 'claude-opus-4-5' --compare-run-effort high max
# big-compare-4 - Sonnet 4.6 (standard context)
session-metrics compare-run 'claude-sonnet-4-6' 'claude-sonnet-4-6' --compare-run-effort low medium
session-metrics compare-run 'claude-sonnet-4-6' 'claude-sonnet-4-6' --compare-run-effort medium highEach compare-run spawns 20 headless claude -p subprocesses (10 prompts, 2 sides). The full matrix landed at 180 subprocesses. Total wall-time was 95 minutes of live inference spread over several 20-minute windows to respect rate limits.
The canonical 10-prompt suite
Every side runs the same 10 prompts, designed to stress different axes of the model’s behaviour.
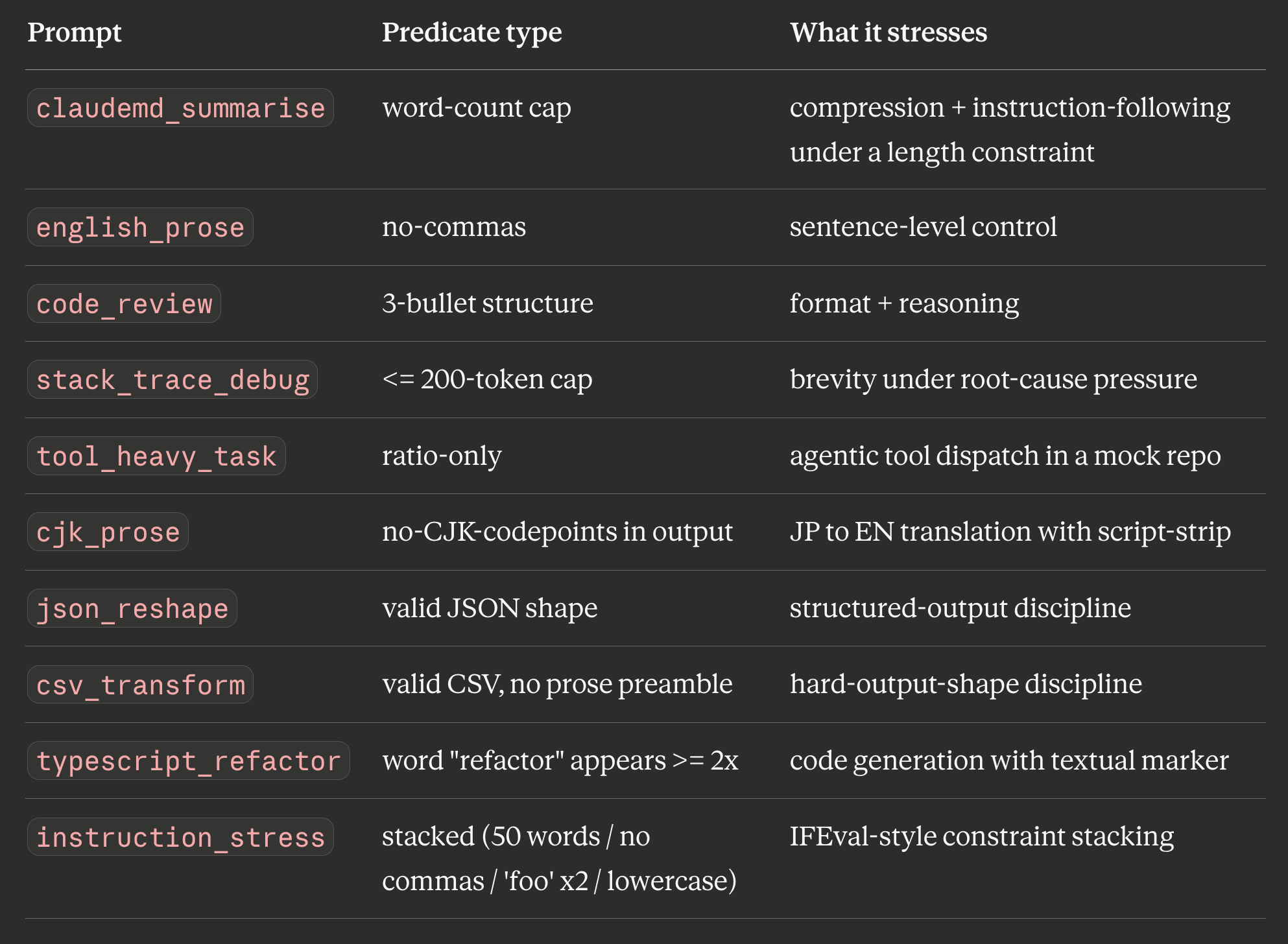
Nine of the ten feed the IFEval pass-rate column. tool_heavy_task is ratio-only because its success criterion is “did the tool call succeed”, not “did the text match a rubric”.
Pricing (per 1M tokens, USD)
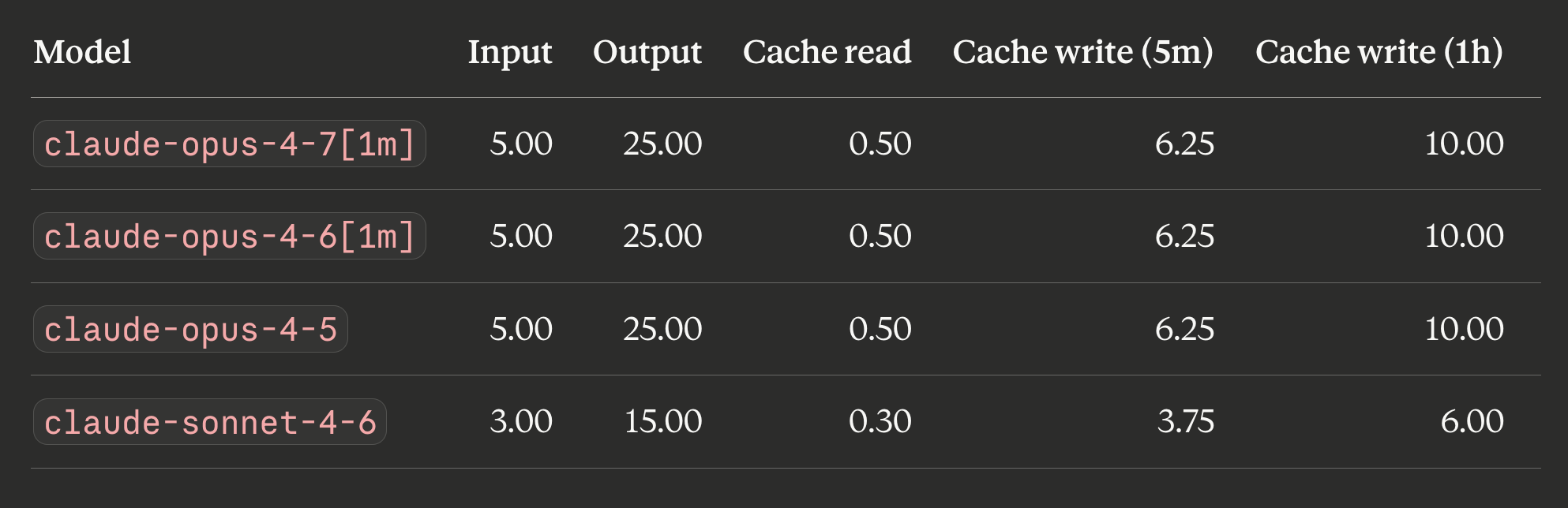
Opus pricing is identical across 4.7, 4.6, 4.5. Any cost differences between Opus variants are purely tokenisation plus behaviour. Sonnet 4.6 is 60 percent of Opus across every column.
How much does cranking the knob actually cost?
The dumbest question is also the most important. What does it actually cost to run the 10 prompts through each combination?
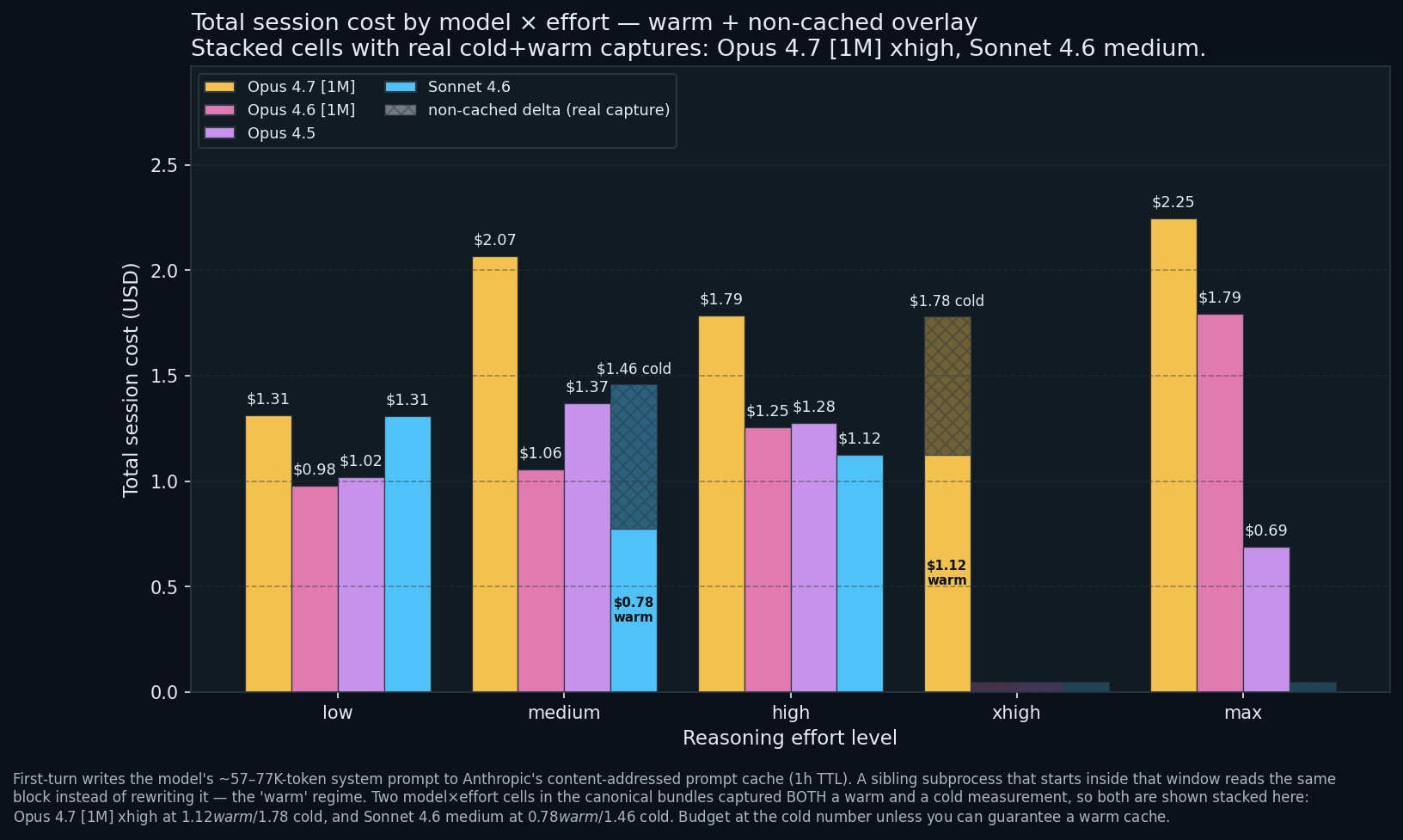
The range. $0.69 to $2.25 on the same 10-prompt workload, a 3.26x spread. Most of it is not attributable to effort: cheapest (Opus 4.5 at max, $0.69) and most expensive (Opus 4.7 at max, $2.25) sit at the same effort level on same-family models. The right question isn’t “which model is cheaper” but “which model, at which effort, with what cache state”.
The cache trap. Two cells where the bundle captured both a warm and a cold run of the same model at the same effort; the chart above stacks them. Opus 4.7 [1M] xhigh: $1.12 warm / $1.78 cold, a 1.59x spread. Sonnet 4.6 medium: $0.78 warm / $1.46 cold, a 1.88x spread. Opus 4.5 at max ($0.69) also ran warm (the 77K-token system prompt was still cached from the preceding low/medium pair at 1-hour TTL, so turn 1 paid ~$0.17 instead of ~$0.78), but the bundle does not contain a second cold-start max capture, so its bar stands alone without a stacked overlay.
In plain English: every Claude Code session sends its own 77K-token system prompt once, and that first send is expensive. If your previous session finished less than an hour ago, Claude Code reuses the cached version. If not, you pay again, which creates up to $0.78 of difference between two otherwise-identical runs. Any sub-1.3x cost ratio in this benchmark is below the observed noise floor.
Output tokens tell a different story
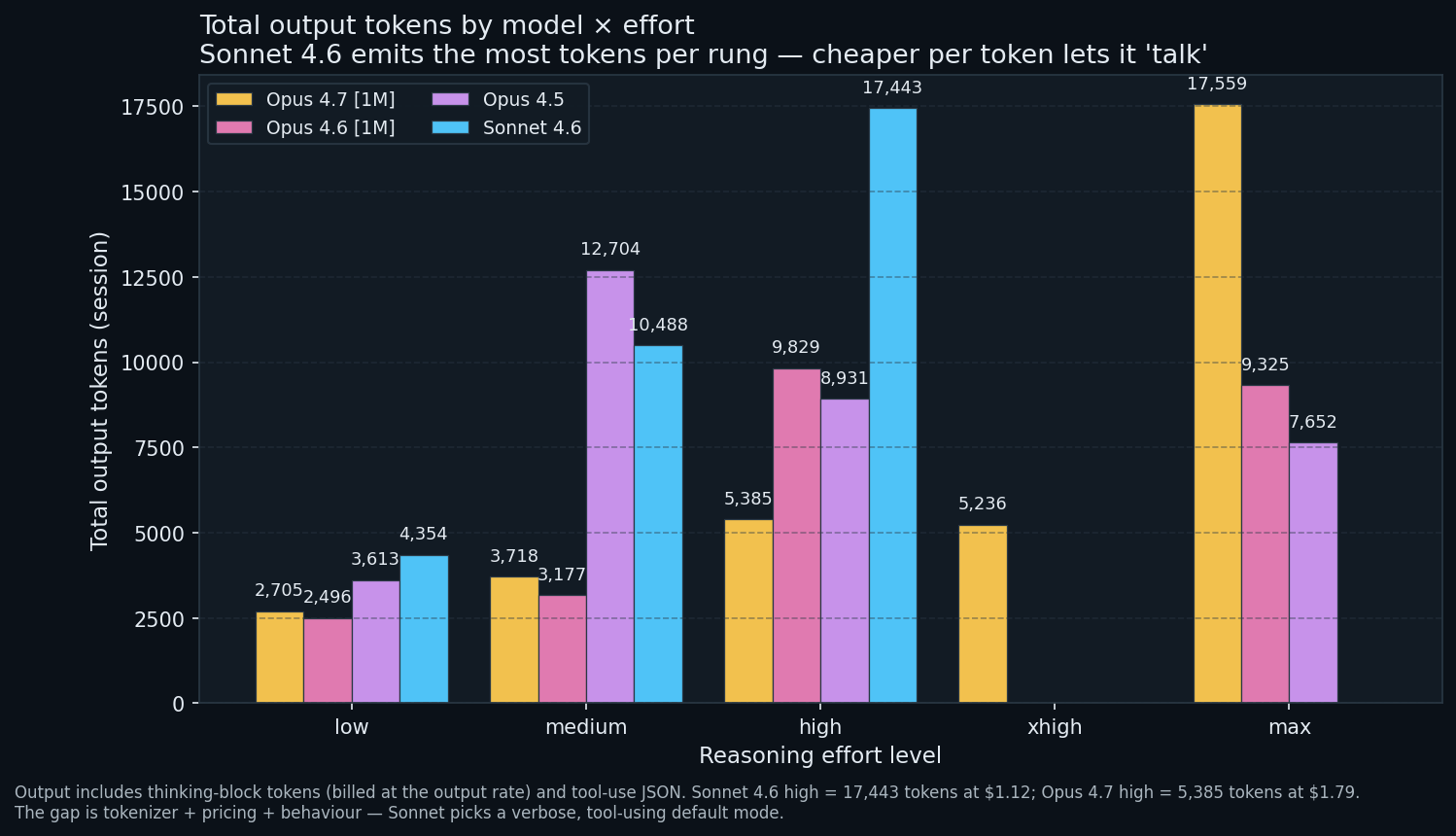
Sonnet 4.6 is the most verbose model here. At high (its top captured rung) it produces 17,443 output tokens vs Opus 4.7 high at 5,385 on the same suite. A 3.24x output gap at the same rung, yet Sonnet’s session cost $1.12 against Opus 4.7’s $1.79. Output verbosity and billing are two conversations, because the models charge different rates per token.
Opus 4.7 max is unique. 17,559 tokens, the single biggest output in the bundle. Opus 4.7 only reaches Sonnet-at-high levels of loquacity at max. Other Opus variants cap out earlier: Opus 4.6 plateaus at ~9,500 across high/max; Opus 4.5 decreases from 12,704 tokens at medium to 7,652 at max (cache-warmth confound again).
Low-rung baselines cluster. Every model produces 2.5K to 4.4K output tokens at low. The spread between rungs is the dial; the floor is the suite.
The chart that changes the recommendation
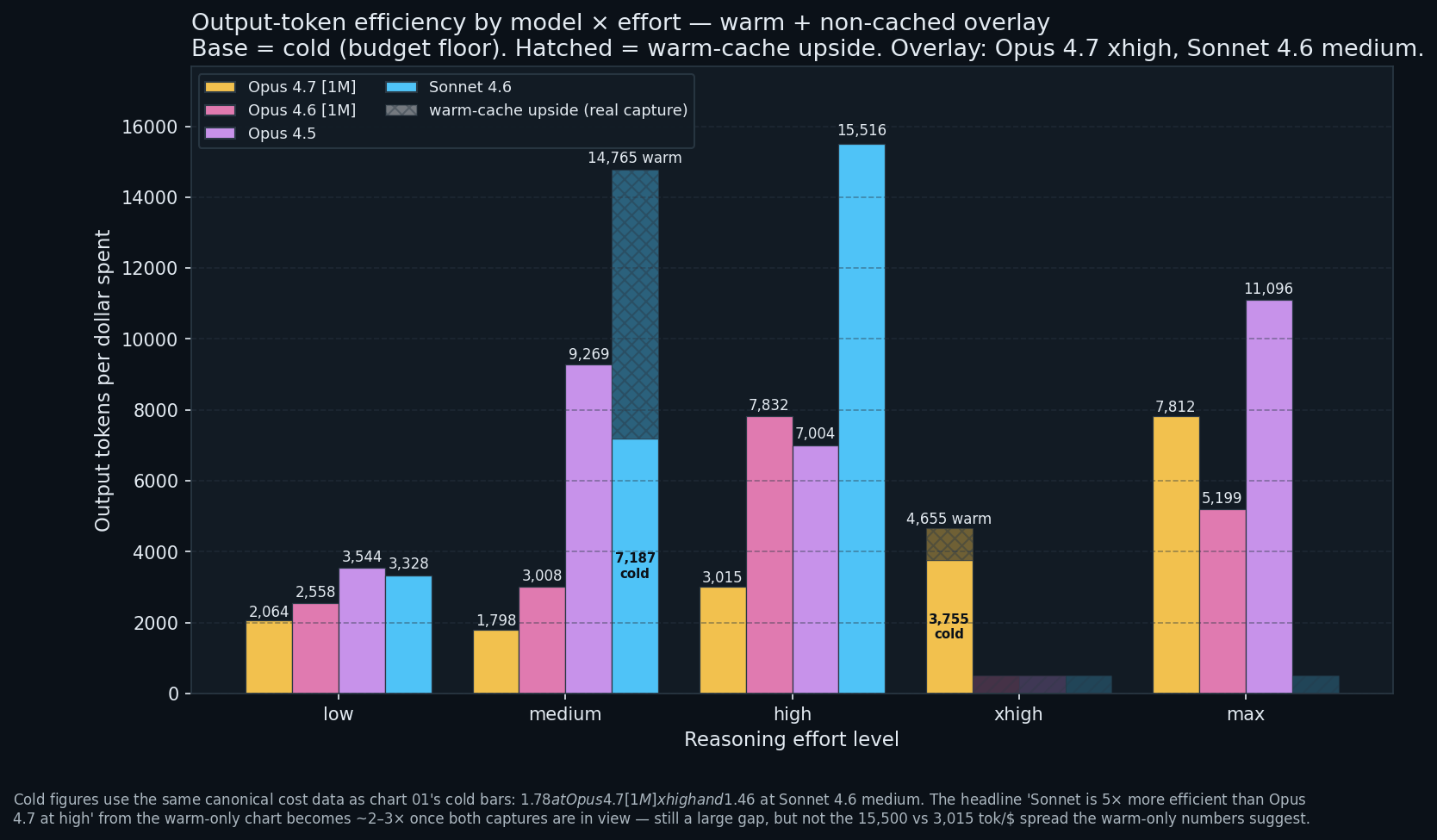
Sonnet 4.6 at high: 15,516 tokens per dollar. The headline. Sonnet 4.6 medium is the more interesting cell now that both captures are plotted: 7,187 tok/$ on the cold canonical run, 14,765 tok/$ on the warm alt. The warm-medium cell is within ~5 percent of the warm-high headline, so if the cache happens to be warm on turn 1, Sonnet medium and high are roughly interchangeable on pure efficiency. Opus 4.7 at high manages 3,015 tokens per dollar, a 5.1x efficiency gap vs Sonnet high at the same rung; that gap compresses to ~2 to 3x once you price Sonnet medium at its cold floor, which is what you should budget against.
Plain English: a dollar buys five times as many words of output on Sonnet 4.6 at high as on Opus 4.7 at high. If you pay for volume (summaries, rewrites, long-form prose), Sonnet is a better deal per dollar even when Opus would give a smarter answer per word. Sonnet’s list price is 60 percent of Opus’s and its default behaviour on the canonical suite produces 2 to 3x more visible output per invocation; those multipliers stack. Opus becomes sensible once the task demands cognitive-quality deltas Sonnet cannot cover.
Low-rung flattening. At low every model sits in the 2,000 to 3,600 tok/$ band. You do not save by picking a cheaper model at the lowest rung, because the first-turn cache tax is fixed overhead that dominates the bill either way.

When does each model actually think?
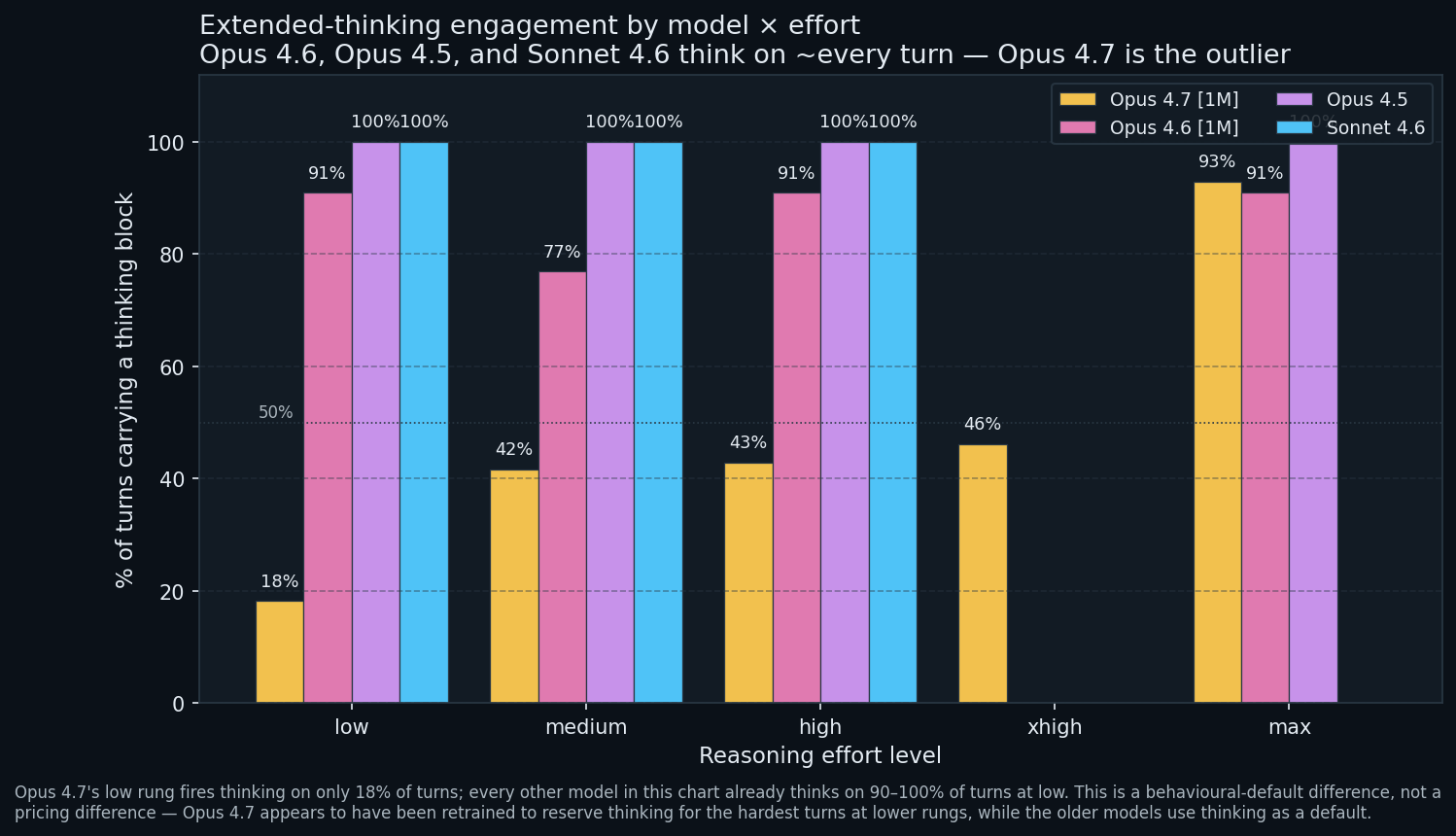
The most surprising chart in the bundle. Every model except Opus 4.7 thinks on roughly every turn, at every effort rung, from low upward. Opus 4.7 at low fires a thinking block on 18 percent of turns. The rest of the time, it just answers.
Opus 4.6, 4.5, and Sonnet 4.6 treat thinking as the default action; their effort dial modulates how long a thinking block runs, not whether one fires. Opus 4.7 modulates both. At low effort it suppresses thinking for trivial turns; only at max does it converge to the older models’ “always think” posture (93 percent).
Plain English: on Opus 4.6 / 4.5 / Sonnet 4.6, “low effort” means “still always thinks, just shorter”. On Opus 4.7, “low effort” means “mostly does not think unless the turn warrants it”. Different product, same /effort interface.
Why this matters if you’re paying.
Here’s where I think a lot of Opus 4.7 users have reported degradation in performance. Anthropic has officially stated that Opus 4.7 with adaptive thinking can be further tuned via prompt steering instructions. “Claude Opus 4.7 calibrates response length to how complex it judges the task to be, rather than defaulting to a fixed verbosity. This usually means shorter answers on simple lookups and much longer ones on open-ended analysis. If your product depends on a certain style or verbosity of output, you may need to tune your prompts.“ So folks may need to change the way they prompt with Claude Opus 4.7 when using adaptive thinking. From my experience, adding at front of prompt, “think critically” shows more improvements as opposed to adding this at end of your prompt.
Thinking tokens bill at the output rate. When Opus 4.6 at
lowthinks on 10 of 11 turns, every one pays the thinking tax. Claude Code stores thinking blocks signature-only (text opaque to every downstream consumer), so you pay output rates for cognition you cannot inspect. Opus 4.7 atlowonly hits you with that tax 18 percent of the time. For “thinking only when necessary” behaviour, Opus 4.7lowis the cheapest path in the current lineup.
Tool calls are Sonnet’s native language
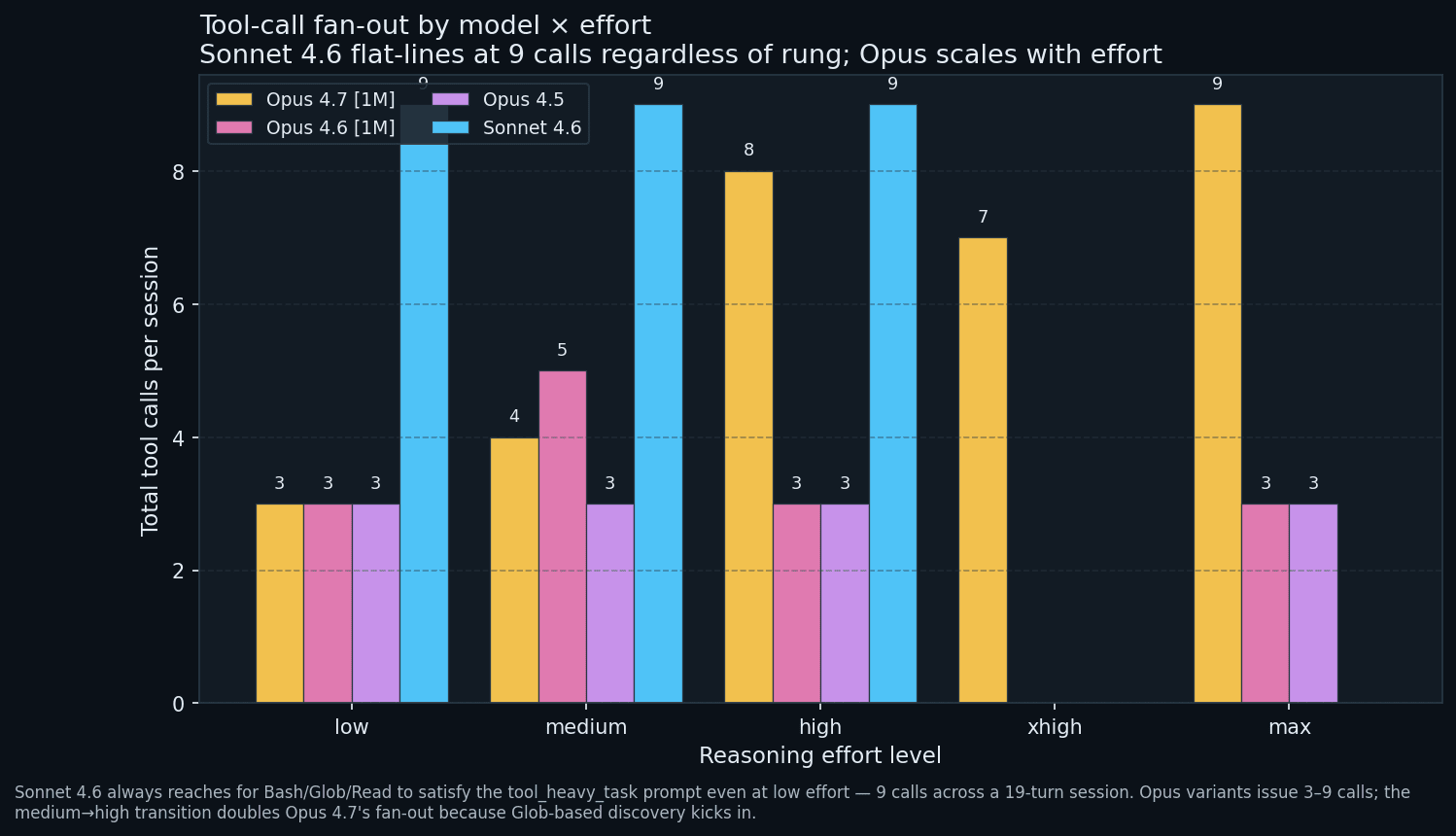
Sonnet 4.6 issues 9 tool calls at every rung, with no sensitivity to effort. Opus variants issue 3 at low/medium, jumping to 7 to 9 only at high and above.
Sonnet treats tool_heavy_task as a multi-step agentic plan from the first prompt: Bash round-trip, Glob, Read against specific files, then synthesise. Opus at low/medium prefers to guess repository structure from the prompt and issue a single Read sweep. Only at high does Opus insert a Glob discovery pass, doubling the tool count.
Plain English: Sonnet acts like an explorer from the first second; Opus at low effort acts like a confident guesser. Different workflow personalities from the same prompt.
The operational tell. If your workload depends on the agent discovering structure rather than being told it, medium -> high is where Opus graduates into tool-assisted behaviour. On Sonnet, that graduation has already happened at low; you cannot turn agentic behaviour off with a lower effort setting.
Turn counts tell the same story
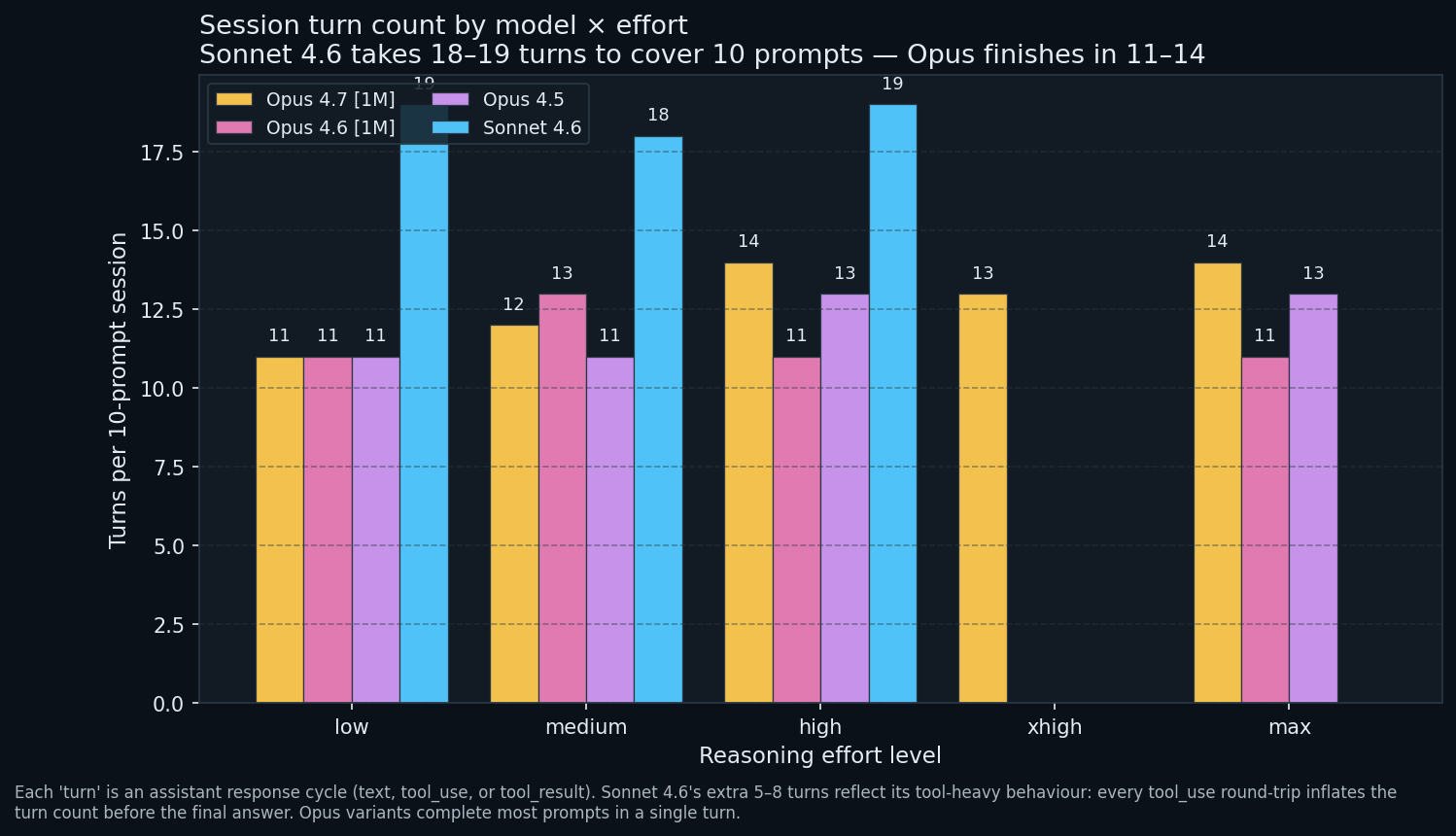
Sonnet 4.6 takes 18 to 19 turns to cover 10 prompts at every effort level. Opus variants finish in 11 to 14 turns. Each turn is an assistant response cycle, including tool_use / tool_result turns that inflate count without producing user-visible text. Sonnet’s extra 5 to 8 turns are the tool-use round-trips the previous chart hinted at; Opus packages more into a single turn.
Practically, this affects latency (more turns = more round-trips = more wall-clock) and session complexity (more tool_result blocks = more JSON to parse if you pipe the session downstream).

Is the knob actually making answers better?
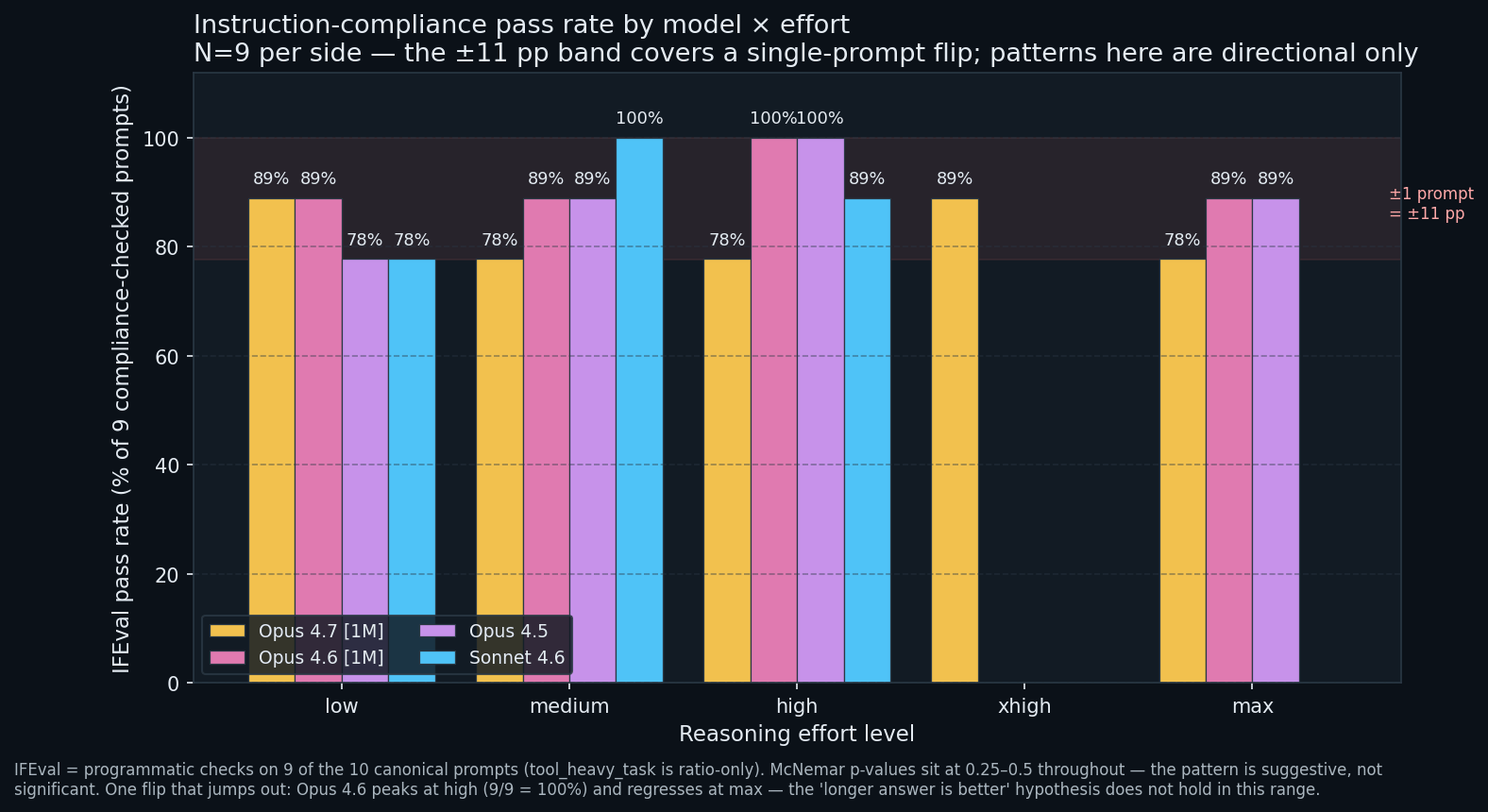
Every compliance-checked run is N = 9 and every cell lands at 78 percent, 89 percent, or 100 percent. Those are the only three possible values. One flip moves the bar 11 percentage points. McNemar p-values across every pair sit at 0.25 to 0.5. The data cannot rule out a coin flip.
Plain English: with 9 prompts, one prompt going from fail to pass moves the rate by 11 points. You cannot draw strong conclusions from a 9-sample survey, and that is why the p-values above refuse to call the differences significant.
The one pattern worth flagging, directionally. Opus 4.6 hits 100 percent at high and regresses to 89 percent at max. Opus 4.7 and Opus 4.5 also regress from high to max. The “longer answer is better” hypothesis does not hold in this range, consistent with stack_trace_debug flipping from pass to fail at max when the model exceeds the 200-token cap while speculatively explaining the root cause.
If you are using reasoning_effort to improve compliance, high is the sweet spot, not max. But be prepared to measure this on your workload. N = 9 cannot commit for you.
The max rung is its own phenomenon
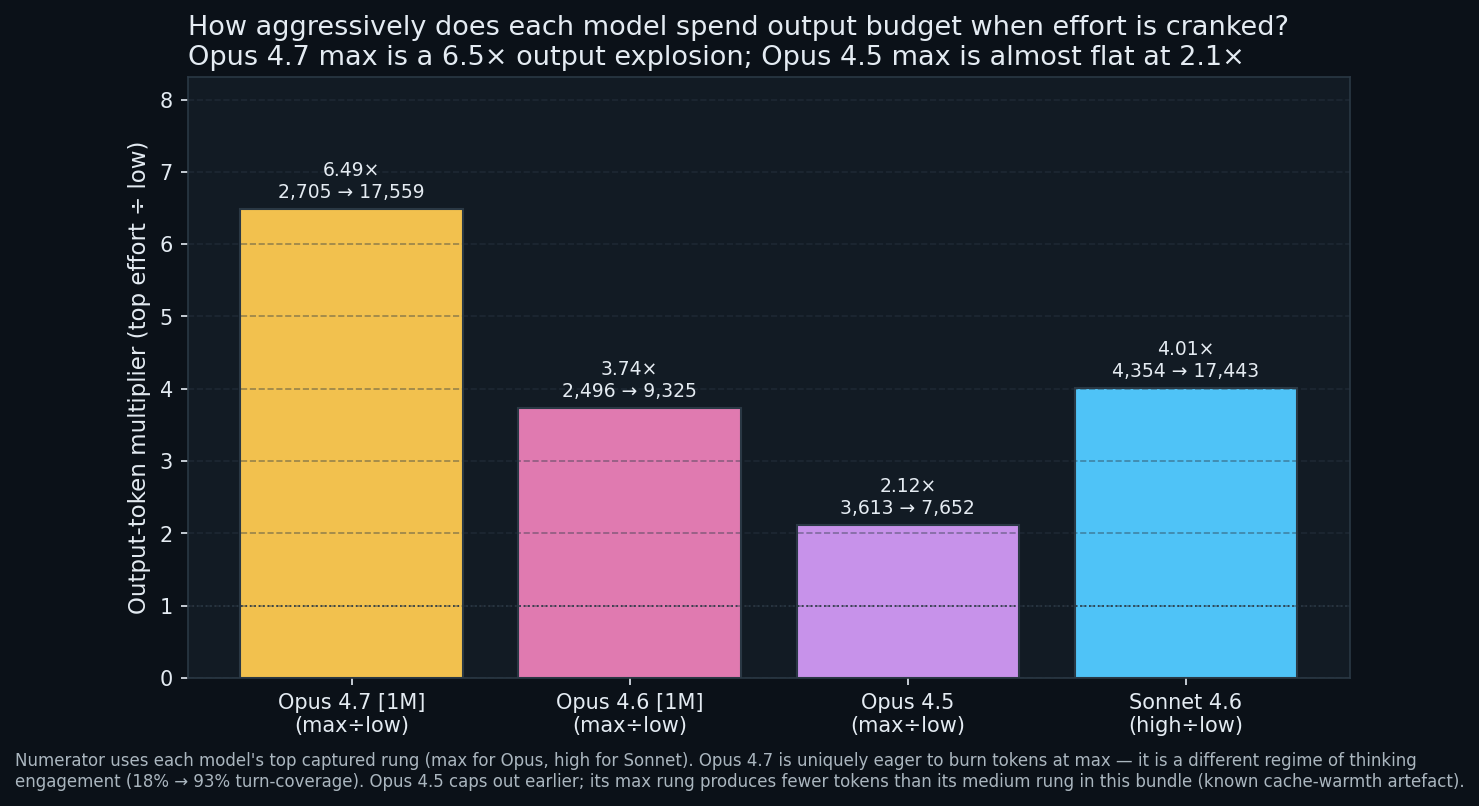
Divide each model’s top-effort output by its low output.
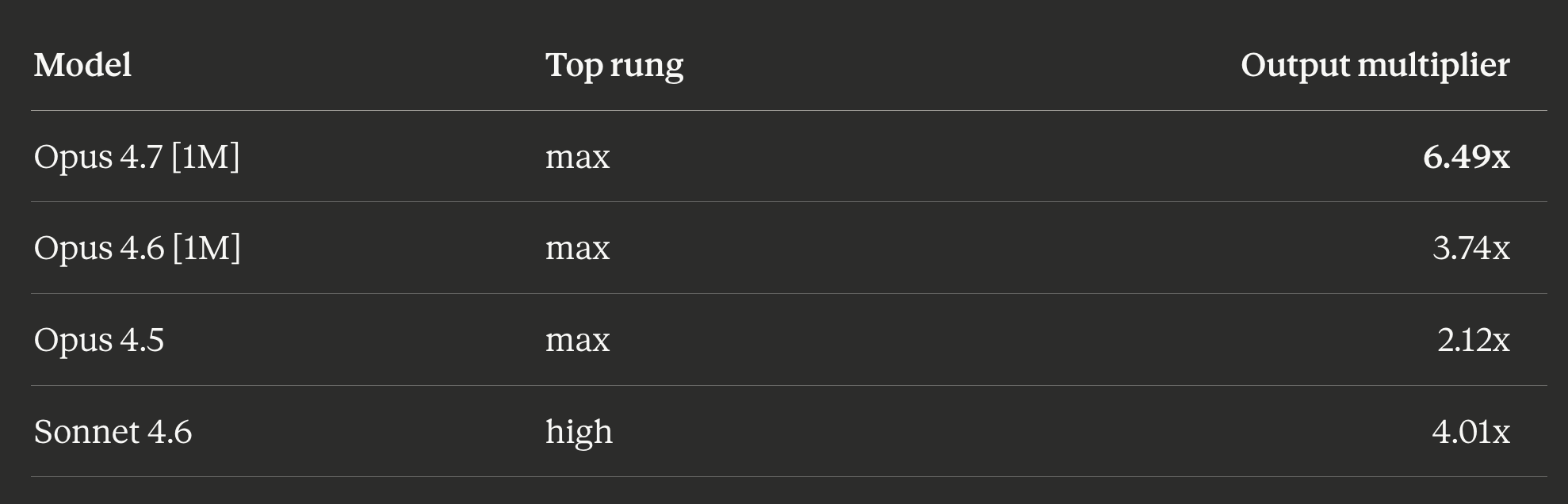
Opus 4.7 at max burns 6.5x more output tokens than at low. That is a regime change, not a rung change. Opus 4.5 by contrast is least reactive: max produces only 2.1x more output than low, and as noted it produced less output than medium in this bundle.
The behavioural implication: the max rung does different things in different generations. On Opus 4.7 it unlocks a “think about every turn” mode. On Opus 4.5 it caps out early. Do not assume the knob has the same range across model families.

Which prompts react to the knob?
One cell per (prompt, model). Each cell is top-rung output divided by low-rung output for that prompt on that model.
The top three rows scream. claudemd_summarise, english_prose, and code_review inflate 4 to 29x when you crank the knob, across every model. These prompts have prose briefs with either soft word-count predicates or no hard output-shape constraint. Extra budget gets spent on commentary, rewrites, and metadiscussion.
The bottom three rows do not move. json_reshape, csv_transform, and tool_heavy_task all sit in the 0.65 to 2.6x band. They have structural predicates (valid JSON, no prose preamble, tool-call round-trips) that absorb any extra budget into a no-op. Raising effort on these prompts makes the session cost more without making the answer meaningfully longer or different.
Sonnet 4.6’s 29x on claudemd_summarise is the single largest effort-driven output explosion in the bundle. The low-rung Sonnet produces a terse 259-token summary. The high-rung Sonnet produces a 7,501-token treatise that overruns the word-count predicate.
Classify your own workload into “prose brief” vs “structured predicate” buckets. If it is mostly prose brief, budget for the knob. If it is mostly structured, default to medium and forget it.
Four models, four shapes
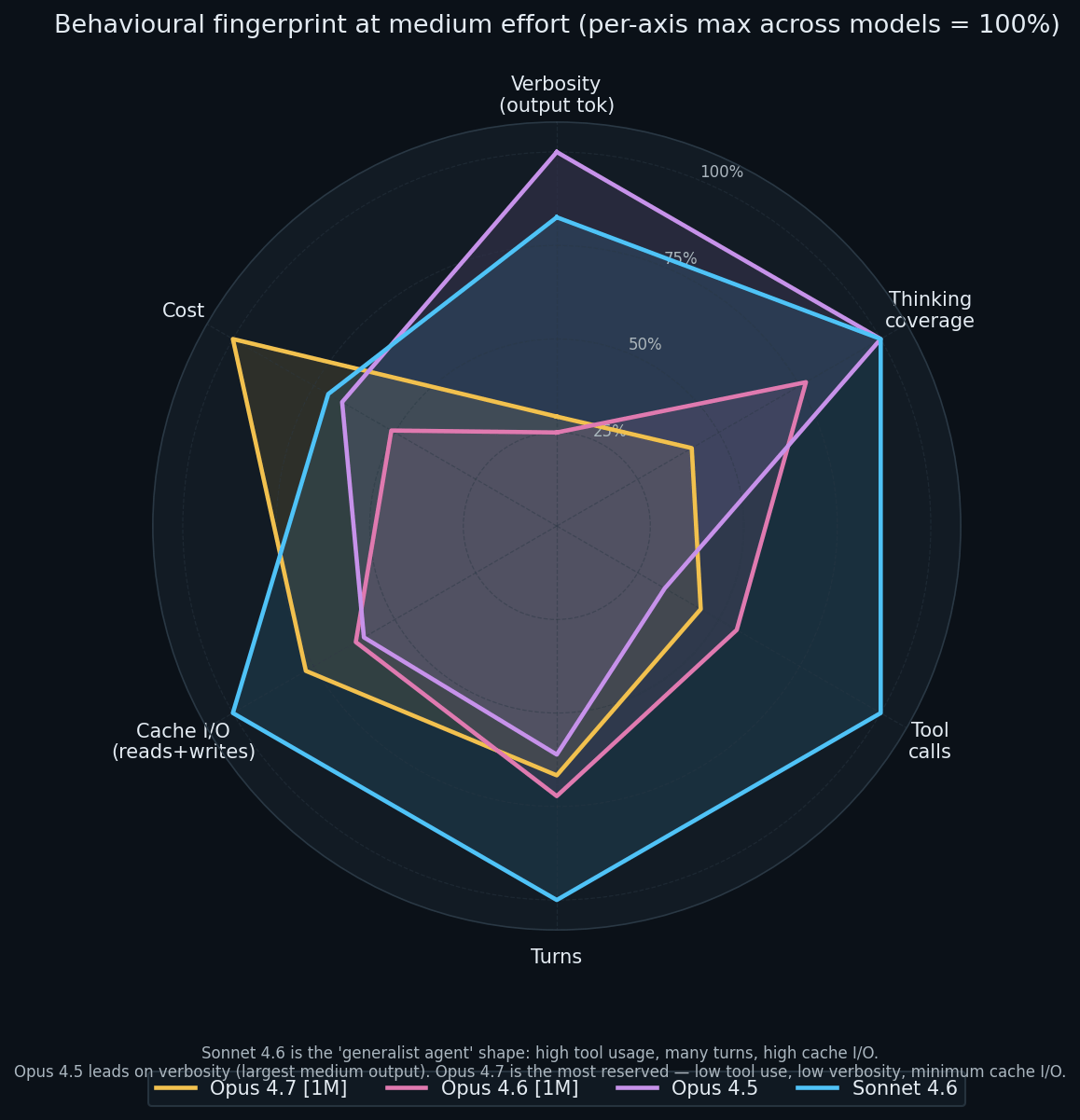
A radar chart per model at medium effort, with six axes: verbosity, thinking coverage, tool calls, session turns, cache I/O, and total cost. Each axis is normalised so the per-axis maximum = 100 percent.
The four models have qualitatively different shapes:
Sonnet 4.6 the “agent”: high tool usage, high turn count, high cache I/O, full thinking engagement. Moderate cost footprint because of the pricing advantage.
Opus 4.5 the “verbose scholar”: peak verbosity in the medium-rung cohort, full thinking, modest tool usage.
Opus 4.6 the “compact middle”: smaller on every axis except thinking coverage.
Opus 4.7 the “focused generator”: highest cost in this slice ($2.07 at medium), lower verbosity, minimum cache I/O, shortest “thinking coverage” petal.
These are different tools for different jobs. The shapes predict where each one shines on your workload.
Cost per correct answer
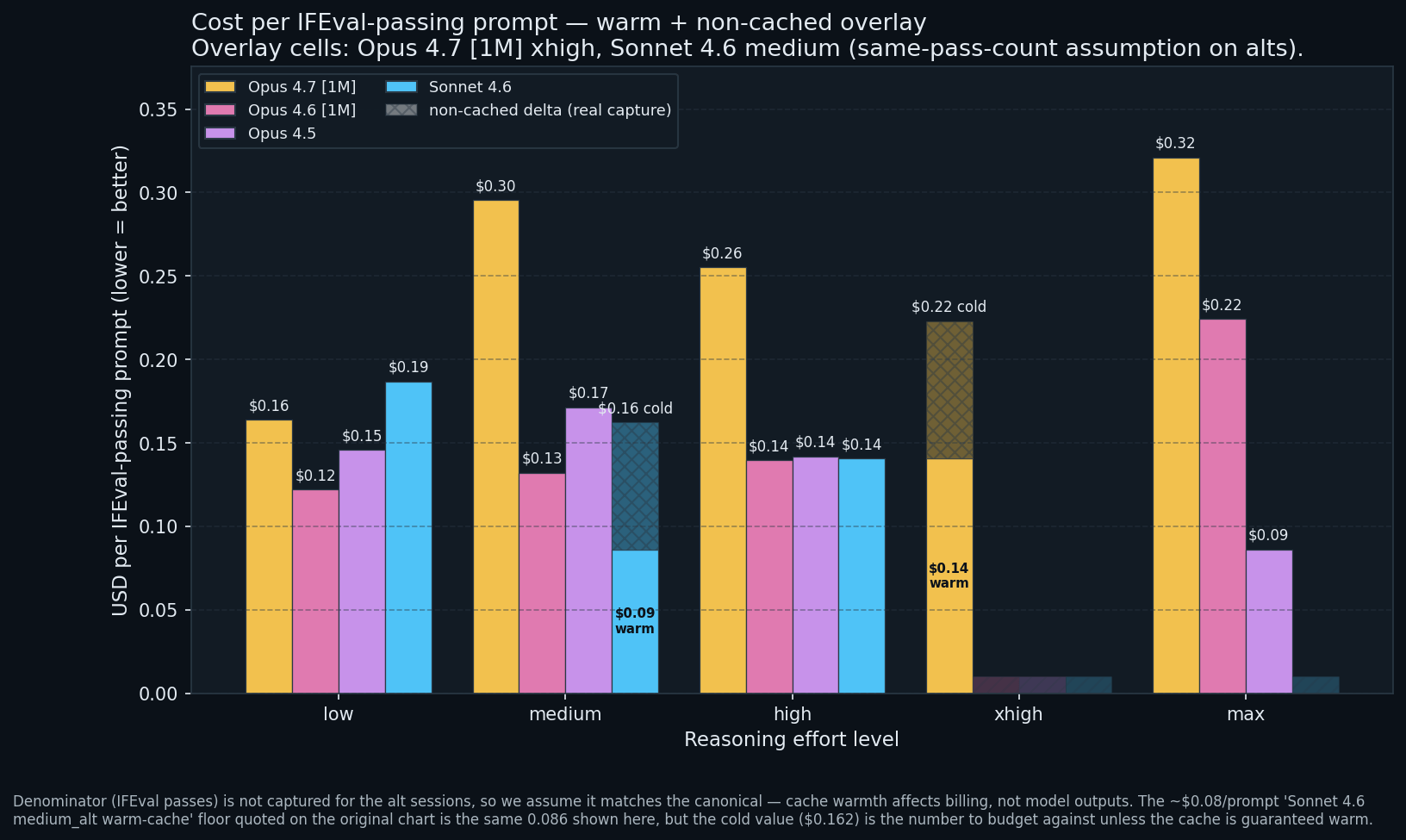
Session cost divided by IFEval passes. Lower is better. Caveat: N = 9, so one flip is ~10 percent per bar.
Sonnet 4.6 at
high: $0.14 per passing prompt. Tied for the bundle’s cheapest non-warm-cache cell with Opus 4.6 and Opus 4.5 athigh.Sonnet 4.6 at
medium: $0.09 warm / $0.16 cold on 9 passes. Same pass count either way; only the denominator moves with cache warmth.Opus 4.7 [1M] at
xhigh: $0.14 warm / $0.22 cold on 8 passes. Budget at the cold number; the warm number is the upside when a sibling subprocess catches the 1h cache window.Opus 4.5 at
max: $0.09 per passing prompt (cache artefact cell; strip the free $0.60 and it is ~$0.17).Opus 4.7 at
max: $0.32 per passing prompt. The most expensive legitimately passing cell. Compliance did not improve (regressed to 7/9 = 78 percent) and cost rose.
For a compliance-bounded workload, high is the right effort rung on any of the four models. The marginal cost per passing prompt is similar ($0.14 for Opus 4.6, Opus 4.5, Sonnet 4.6 all at high). max only degrades the ratio.
Where does the medium-effort dollar actually go?
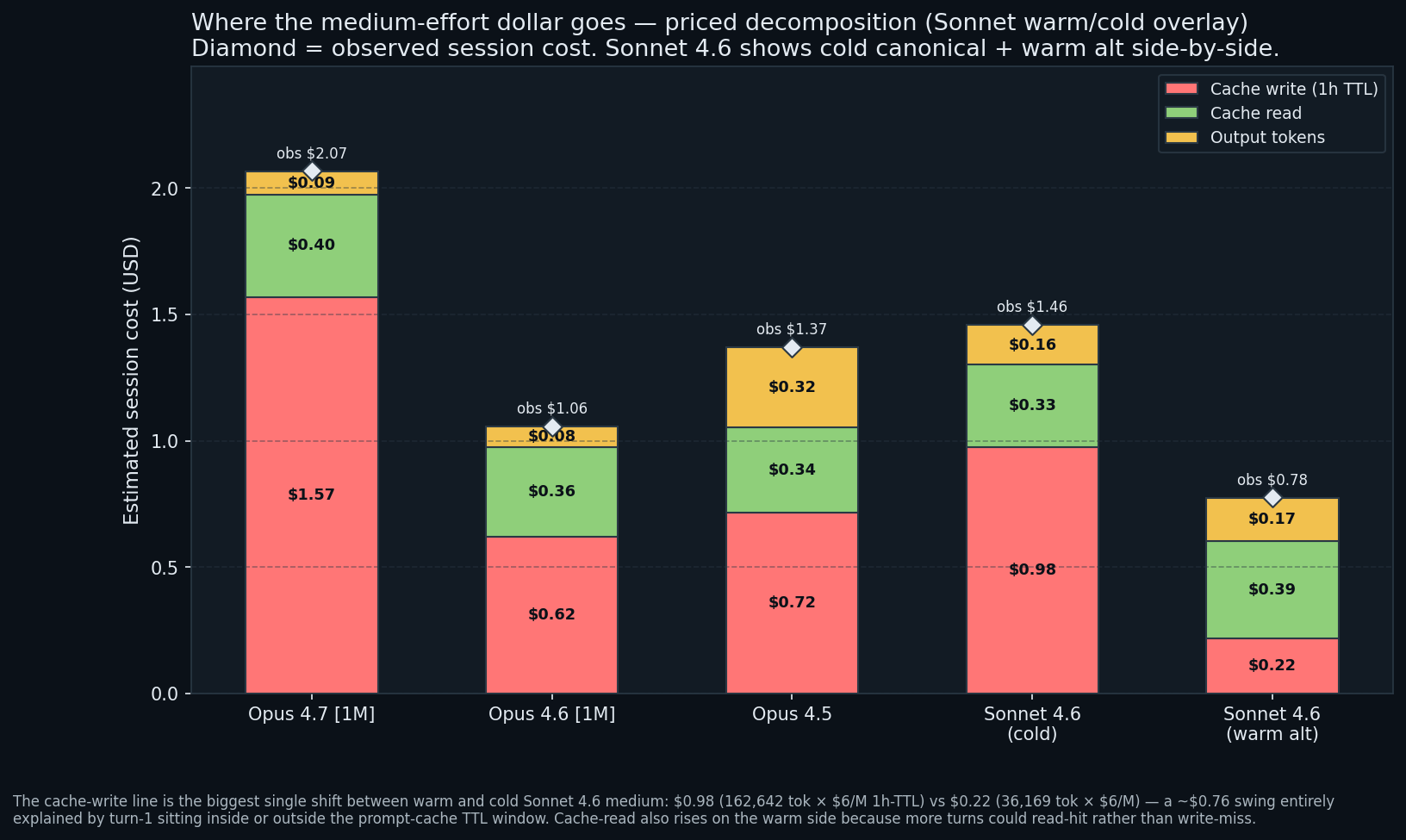
Stacked bar of the priced token-class decomposition at medium effort per model. Cache writes (red, 1h TTL) dominate every Opus bar. Output tokens (yellow) are a footnote on Opus sessions and a meaningful component on Sonnet’s.
Biggest cost driver: the first-turn cache write. Claude Code’s headless subprocess writes its 77K-token system-prompt block to the 1-hour TTL cache on turn 1. That write costs ~$0.78 on Opus or ~$0.47 on Sonnet. Every subsequent turn reads from that cache at $0.50/M (Opus) or $0.30/M (Sonnet).
Three practical implications. The first-turn cache tax is fixed overhead, invariant to effort; a 10-prompt session spreads $0.78 over 10 prompts, a single-prompt session pays the whole $0.78, so bundle your work. Claude Code uses the 1h TTL tier 100 percent of the time, an unavoidable ~25 percent uplift over the 5-minute tier, with no claude -p flag to override. And Opus 4.7 medium is the most expensive cell at $2.07, with $1.57 of that in cache writes (the medium-rung capture had 2x the cache-write tokens the low-rung did: 157K vs 84K).
Sonnet 4.6 medium is shown as two side-by-side stacks: the cold canonical ($1.46) and the warm alt ($0.78). The single line that moves most between them is cache-write: $0.98 on the cold run (162,642 tokens × $6/M at the 1h TTL rate) vs $0.22 on the warm run (36,169 tokens × $6/M), a ~$0.76 swing explained entirely by whether turn-1 landed inside or outside the prompt-cache TTL window. Cache-read rises slightly on the warm side because more later turns read-hit instead of write-missing. On both stacks, output tokens are the only non-cache line that contributes a visually meaningful slice ($0.16 of the $1.46 cold total). Sonnet’s output rate is 60 percent of Opus’s and its output count is ~3x Opus’s, so the dollar product is similar but the share going to output is larger.
Where should you spend?
The benchmarks do not produce a single “best model x best effort” answer. They do produce the following operating rules for the four combinations tested.
Prose briefs (reports, rewrites, summaries). Default to Opus 4.6 or Sonnet 4.6 at medium ($1.00 to $1.46 per 10-prompt run). Opus 4.7 at the same rung paid 1.4 to 2x more for comparable output. For most bytes per dollar, Sonnet 4.6 at high at ~15,500 tokens/$ is the peak. Avoid Opus max unless you specifically want metacommentary.
Structured outputs (JSON, CSV, tool calls). Effort barely matters. Default to the cheapest (model x rung) that hits your compliance target: Opus 4.6 or 4.5 at low (~$1.00). Sonnet 4.6 is cost-competitive but will dispatch tools you did not ask for.
Agentic work (multi-step tool use, repo exploration). Sonnet 4.6 is the natural fit; already in agentic mode at low (9 tool calls, 19 turns, full thinking). On Opus, medium -> high is the phase transition. Effort below high is a false economy here. Anthropic has said Claude Opus 4.7 is better for long-horizon agentic work. Obviously, my tests are fairly limited compared to Anthropic.
Compliance-bounded workloads (writing to a spec). high is the sweet spot on three of the four models. max regresses compliance on Opus 4.7 and 4.5. Measure on your own content; N = 9 is too small to commit.
Caveats
Four confounds worth stating plainly:
Cache warmth. Two cells ran warm on turn 1 (Opus 4.5 max, Sonnet 4.6 medium alt capture) and saved 37 to 47 percent of the cold-start cost. A third, Opus 4.7 [1M] xhigh, has one warm and one cold capture both available, so charts 01, 03, 11 stack them directly. If you are comparing to a price list, always compare to the cold-start number.
Same-model comparisons inflate confidence. The compare-run pairings here were same-model-vs-same-model, so the ratios are effort plus variance, not model. The cross-model conclusions came from aligning separate bundles at the same effort level, which is weaker evidence than a true cross-model paired run would be.
IFEval at N = 9 is directional. McNemar p-values at 0.25 to 0.5 throughout. Treat “A beat B by 1 prompt” as null. A proper compliance benchmark wants N >= 30.
Claude Code’s system prompt is large. About 77K tokens of tooling and context is the floor for every session. Note this 77K tokens is for my Claude Code setup with it’s CLAUDE.md and MCP/Skills/Agents/Tools. That is the cache-write overhead that dominates chart 12. Results on the Anthropic SDK directly (with a user-supplied 500-token system prompt) would see a completely different cost-composition pie. Claude Code is not a tokenizer-clean comparator for raw API pricing; it is a full agent harness.
Subscription allowance was raised to match. Anthropic lifted paid-tier limits when Opus 4.7 shipped. Boris Cherny posted on Threads: “We’ve increased limits for all subscribers to make up for the increased token usage.” The dollar figures above are API-equivalent billing and are unaffected. On Pro / Max / Team / Enterprise the headroom story is softer than the raw token growth suggests. More on this in Six Things to Change in Your Claude Code Setup After Upgrading to Opus 4.7.
Reproduce this benchmark
Prerequisites: an active Claude subscription (Pro / Max / Team / Enterprise) and claude --version returning a current build on your PATH. The skill uses claude -p headless. It inherits your subscription auth and rate limits. No API key involved.
Install the plugin and run the full matrix:
/plugin marketplace add centminmod/claude-plugins
/plugin install session-metrics@centminmod
/reload-plugins
# Each line spawns 20 headless `claude -p` subprocesses.
# Budget 15 to 25 minutes per compare-run invocation on a warm connection.
session-metrics compare-run 'claude-opus-4-7[1m]' 'claude-opus-4-7[1m]' \
--compare-run-effort low medium --yes --output md html
session-metrics compare-run 'claude-opus-4-6[1m]' 'claude-opus-4-6[1m]' \
--compare-run-effort high max --yes --output md html
# ... and so on for the rest of the matrix above.For a single-model ladder shortcut:
session-metrics benchmark-effort --model 'claude-opus-4-7[1m]'That runs all five rungs of one model in one shot.
Numbers will differ from this bundle’s captures, because cache state and subscription-level latency and caching cannot be controlled between runs. The shape of the conclusions should reproduce; the specific dollar figures will not.
What I learned
Effort is an output-token dial. Not an input dial, not a naive quality dial. Input is fixed at the prompt’s word count; output is where every effort-driven dollar lives, and it grows by up to 6.5x across the knob’s range on the newest model.
Opus 4.7 is a different product. Older Opus variants and Sonnet 4.6 think on every turn by default. Opus 4.7 decides per turn whether to think, and that decision happens inside the model, not inside the effort flag. The flag controls how often it chooses to think, not whether thinking is on.
Sonnet is the volume leader; Opus is the per-word capability lead. Sonnet 4.6 at high delivers 5x more bytes per dollar than Opus 4.7 at high. Bandwidth-bound: pick Sonnet. Capability-bound on a hard problem: Opus at high or max is the ceiling. The two are not interchangeable.
The knob has diminishing returns. IFEval compliance peaks at high on three of four models and regresses at max. Output tokens on Opus 4.5 peak at medium and fall at max. Use max when you specifically want research-mode output.
Cache warmth is a first-order cost driver that can move a bill by 40 percent on identical model and identical effort. session-metrics fires an advisory when two sides drift by 10 pp or more; use it.
What’s next
Five things for the next iteration: cold-start every side with a 61-minute wait between invocations to kill cache-warmth artefacts; scale IFEval to N >= 30 so McNemar can reject; do true cross-model compare-run pairs for tighter error bars; add duration_seconds to bench-data.json for a latency chart; and retain per-content-block token counts (thinking / tool_use / text splits) so the reader-visible-output share stops being approximate.
If you found this interesting, check out Claude Opus 4.6 vs Opus 4.7 Effort Levels And Prompt Steering Benchmarks.
If you’re interested in practical AI building for web apps, developer workflows, and infrastructure, subscribe for future posts. You can also follow my shorter updates on Threads (@george_sl_liu) and Bluesky (@georgesl.bsky.social) or subscribe and follow along.