
I Ran Opus 4.6 and 4.7 on the Same 10 Prompts at 1M Context. The Newer Model Cost 2.17x More
Opus 4.7 [1m] at its shipping xhigh default cost 2.17x Opus 4.6 [1m] at its shipping high default, for +11.1 pp IFEval

Anthropic just shipped Claude Opus 4.7. Both it and Opus 4.6 now run at 1 million tokens of context. If you pay for Claude Code, the obvious question is: should I switch my default from 4.6 to 4.7?
I opened a fresh Claude Code session, typed one command, walked away, and four minutes later I had the answer. Same 10 prompts, one run on each model, both at 1M context, both at the effort level the model ships with by default. Apples-to-apples.
Short version: Opus 4.7 cost 2.17x more than 4.6 for the same 10 prompts. Instruction-following went up 11.1 percentage points. One single prompt cost 15.70x more on the newer model. For the work I do day to day, that trade might not be worth it. However, Anthropic has also raised paid subscription users’ usage limits to account for the increased token usage by Opus 4.7. So if your usage scenarios benefit from Opus 4.7 over Opus 4.6, it still might be worth it. Test and find out.
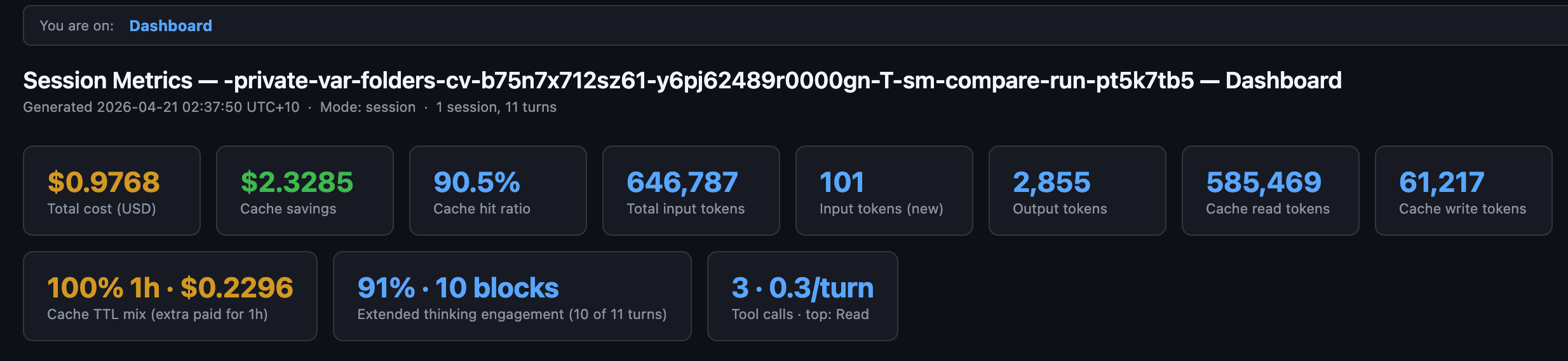
The longer version, with per-prompt numbers and a framework for when the newer model is worth it, is what the rest of this post walks through. All three numbers came out of my session-metrics skill’s new compare-run command, which I shipped to my public Claude Code plugin marketplace.

Background
Two days ago, I wrote about publishing my Claude Code plugin marketplace at ai.georgeliu.com/p/my-claude-code-plugin-marketplace. The headline plugin in that marketplace is session-metrics. It reads Claude Code’s own transcript logs and tells you exactly how many tokens and dollars each turn cost, where your cache helped or hurt, and which prompts drove your bill.
The v1.7.x line added a feature called compare-run. You give it two model IDs, it spawns two headless Claude Code processes under the hood (one per model), feeds each the same 10 test prompts, and emits a paired comparison report plus per-side dashboards. No API key needed, it just uses your existing Claude subscription.
I had not actually run a like-for-like Opus 4.6 vs 4.7 comparison at 1M context myself yet. So I did.
The command was literally this:
/session-metrics compare-run claude-opus-4-6[1m] claude-opus-4-7[1m] --compare-run-effort high xhighThe [1m] suffix tells Claude Code to use each model’s 1 million token context tier. The --compare-run-effort high xhigh flag pins each side to its model’s shipping default: Opus 4.6 defaults to effort level high, Opus 4.7 defaults to xhigh (more on effort levels in the glossary below). Passing both explicitly is redundant but makes the numbers self-documenting when I look at the report three months from now.
TL;DR
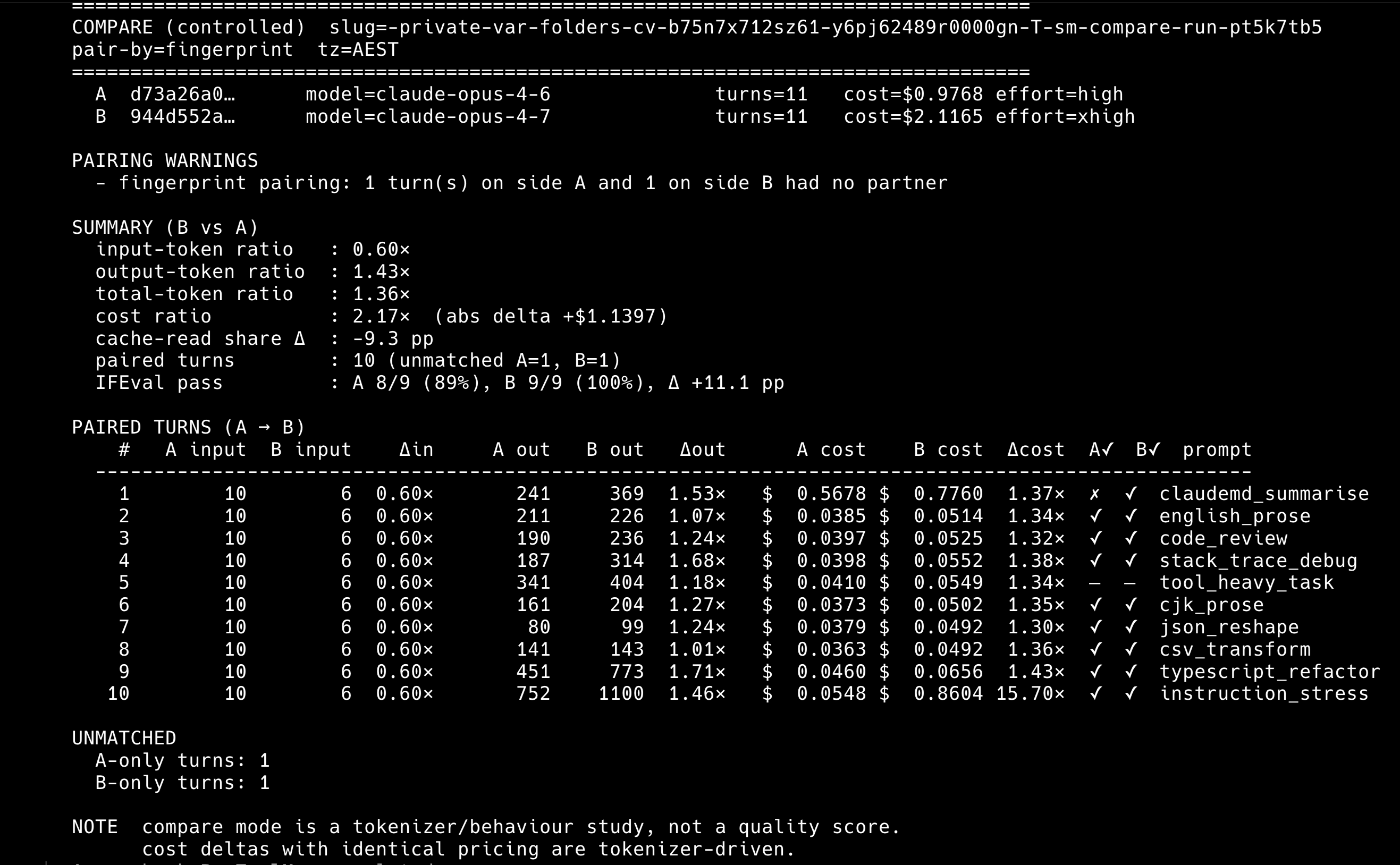
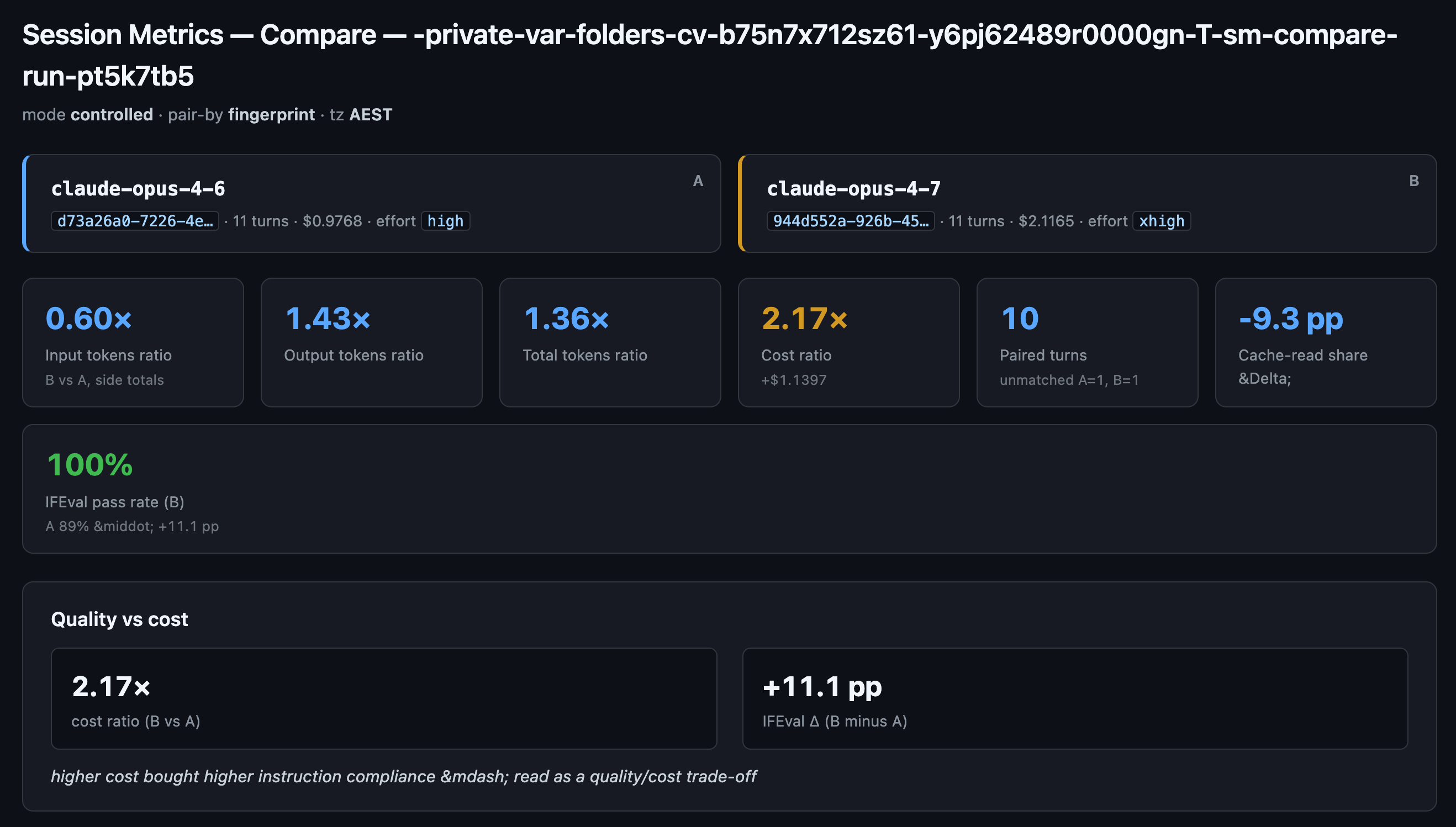
Cost ratio, Opus 4.7 [1m] xhigh over Opus 4.6 [1m] high: 2.17x. Absolute delta: +$1.1397 on 10 prompts.
Input tokens (net new, uncached): 0.60x (4.7 emits fewer new input tokens per prompt)
Output tokens: 1.43x (4.7 writes longer responses)
Total billable tokens: 1.36x
IFEval pass rate: A 8/9 (89%), B 9/9 (100%). Delta: +11.1 pp
Skill’s decision-framework verdict: very-expensive bucket. Stay, or use Opus 4.7 [1m] selectively (e.g. code review only).
Key terms (short glossary)
Skim whatever you already know. These are the terms the rest of the post leans on.
Token: the unit Claude counts for billing. Roughly 4 English characters per token, so a short prompt is around 100 tokens and a long technical article might be 5,000.
Context window: how much text Claude can see at once. The default Opus tier sees around 200K tokens. The
[1m]suffix means 1 million tokens, useful when you feed in large codebases or long documents. Both sides of this comparison use[1m].Effort level: a Claude Code setting (
/effort low | medium | high | xhigh | max) that controls how hard the model thinks before answering. Higher effort usually means more hidden “thinking” tokens and better answers, at a higher cost. Opus 4.6 defaults tohigh. Opus 4.7 defaults toxhigh, which uses adaptive thinking (the model decides per turn how hard to think instead of spending a fixed budget every time).Turn: one round-trip exchange. A user message plus the model’s response is one turn. When the model calls a tool and the tool replies, that tool result is a separate turn too.
Cache read / cache write: once Claude has processed a big chunk of your system prompt or context, Claude Code stores it in a short-lived cache. Follow-up turns pay a cheap cache-read fee instead of re-processing the whole thing. Cache writes cost more up front but save money on every turn after. A lot of the cost story in this post lives in these two buckets.
1-hour TTL vs 5-minute TTL: Claude Code can write cache entries that live for either 5 minutes or 1 hour. The 1-hour tier costs 60 percent more per write token but keeps the savings flowing over longer sessions.
IFEval: a public benchmark (from Zhou et al. 2023) that tests whether a model followed a specific instruction literally. Example: “Your reply must contain exactly 3 paragraphs and mention the word apple twice.” IFEval grades the output programmatically and you get a pass rate like 8 of 9 prompts passed.
pp (percentage points): the literal arithmetic difference between two percentages. 100 percent minus 89 percent is 11 percentage points, written
+11.1 pp. That is not the same thing as saying “11 percent better”, which would be a ratio.Canonical suite: a fixed set of 10 test prompts that ship with
session-metrics, picked to cover the content shapes Anthropic’s own tokenizer write-up measured (English prose, CJK prose, code review, refactors, JSON reshape, CSV transform, etc.). Running the same 10 prompts on two models gives you a clean head-to-head number.
Methodology
Both sides ran inside compare-run on the same day, back-to-back, same workstation, same Claude subscription.

The “10 prompts, 11 turns” asymmetry is by design. One of the 10 prompts (tool_heavy_task) asks Claude to call a tool, and the tool’s reply counts as its own turn, so that prompt generates 2 turns instead of 1. That’s why each side has 11 turns total. IFEval compliance is scored on the 9 prompts that have deterministic grading; tool_heavy_task is excluded because its success criterion is “did the tool call succeed”, not “did the text match a rubric”.
The 10 prompts, in pairing order: claudemd_summarise, english_prose, code_review, stack_trace_debug, tool_heavy_task, cjk_prose, json_reshape, csv_transform, typescript_refactor, instruction_stress.
Pairing is by fingerprint. One turn on each side had no partner (the tool_heavy_task tool-result turn lands at slightly different indices on the two sides), so 10 of 11 turns are paired. The unpaired turns are excluded from the per-prompt ratios below but count in the per-session totals.
Per-session totals
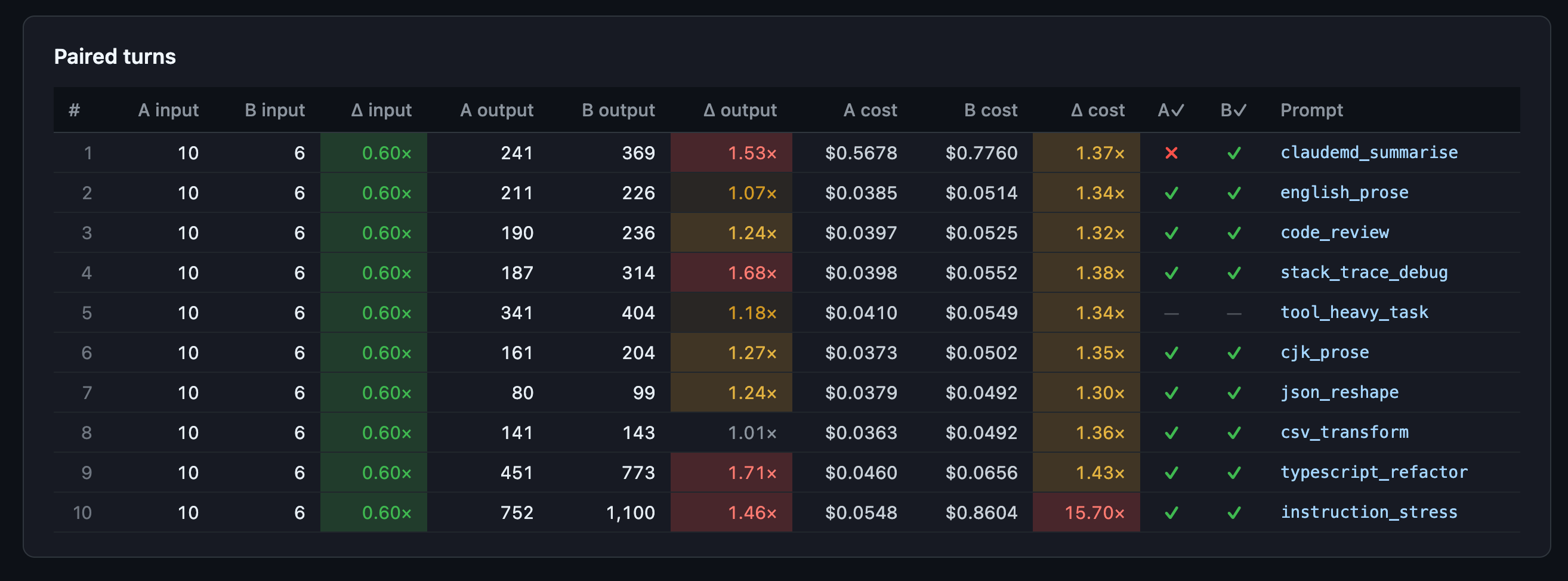
Four things jump out.
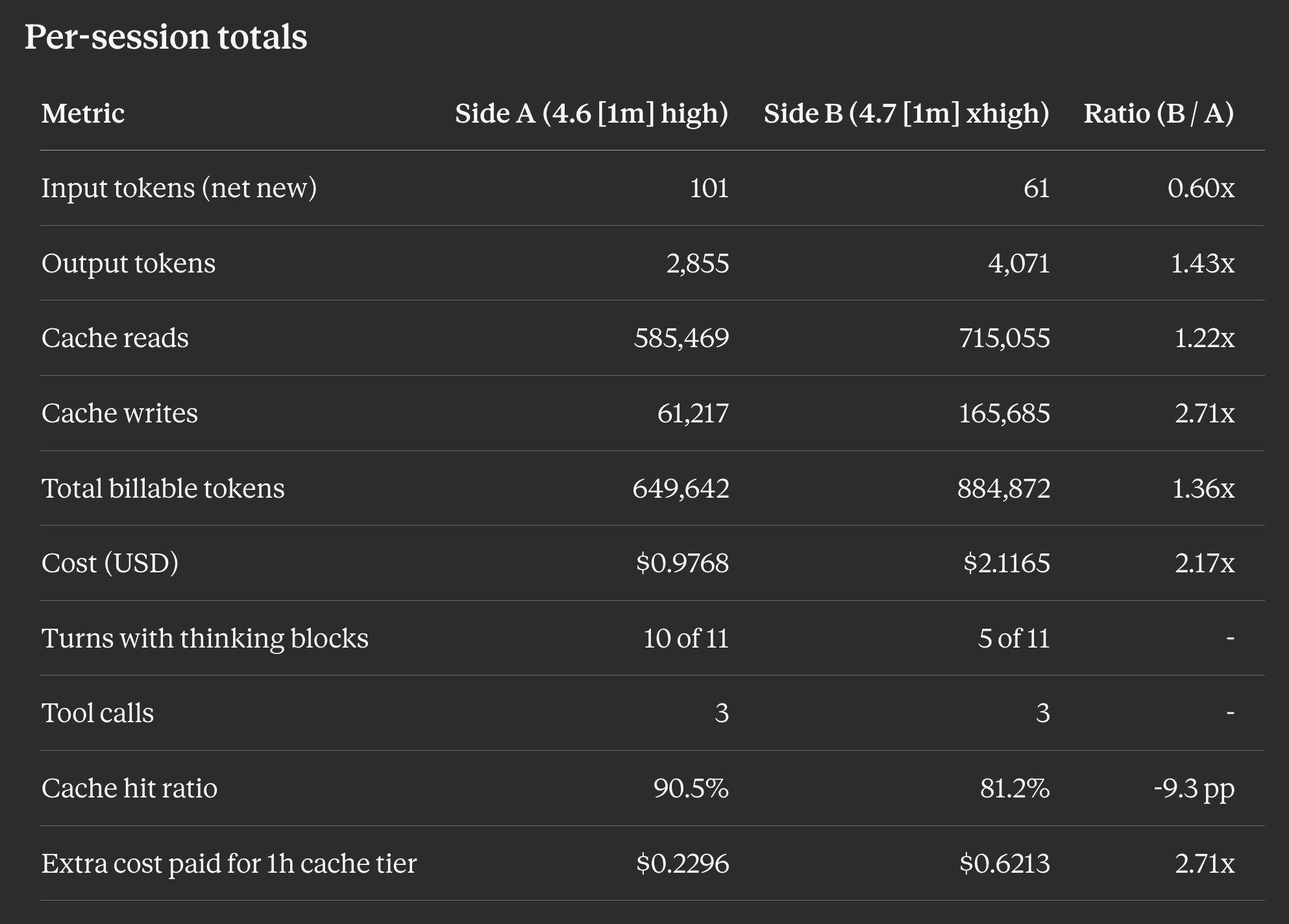
Opus 4.7 uses fewer uncached input tokens per prompt (6 vs 10). The suite prompts are short, so this is a tokenizer difference, not a content difference. The tokenizer is the piece that converts your text into the number-units Claude actually bills on, and Opus 4.7 ships with an updated one that packs the same English prompts into slightly fewer input tokens.
That direction reverses on larger inputs. The first-turn cache write (Claude Code’s own system prompt) came out at 76,675 tokens on 4.7 vs 56,168 on 4.6, a 1.37x ratio, which matches the “up to 1.35x more tokens than Opus 4.6 for the same input” figure I covered in Six Things to Change in Your Claude Code Setup After Upgrading to Opus 4.7. Short user prompts shrink on 4.7; long system prompts and code blobs grow. Same tokenizer, opposite signs depending on what you feed it.
Opus 4.7 writes longer outputs (1.43x). Part of that is xhigh effort using more adaptive thinking on the hard prompts (thinking tokens are billed as output tokens even though you never see them in the reply). Part of it is simply the model being more verbose on the refactor and instruction-following prompts.
Opus 4.7 wrote 2.71x more data into cache than 4.6. That’s two things: the first-turn cache write where Claude Code stores its system prompt for reuse (76,675 vs 56,168 tokens because of the tokenizer change above) plus a larger final-turn cache write on the instruction_stress prompt. Both sides used the 1-hour cache-write tier. 1-hour writes cost 60 percent more per token than the 5-minute tier ($10 per million tokens vs $6.25 per million on Opus 4 series), but they keep the cached content alive for much longer. The extra-cost-paid row is where a lot of the absolute dollar delta lives.
Opus 4.7’s cache hit ratio landed 9.3 percentage points lower, meaning a smaller share of its total token traffic came from cheap cache reads. The skill has an advisory that fires when the two sides drift by 10 pp or more, so we are just under the threshold. Some of that is simply warm-cache asymmetry between back-to-back runs (Side B started slightly warmer than Side A did).

Per-prompt breakdown
This is where the cost story stops being a clean ratio.
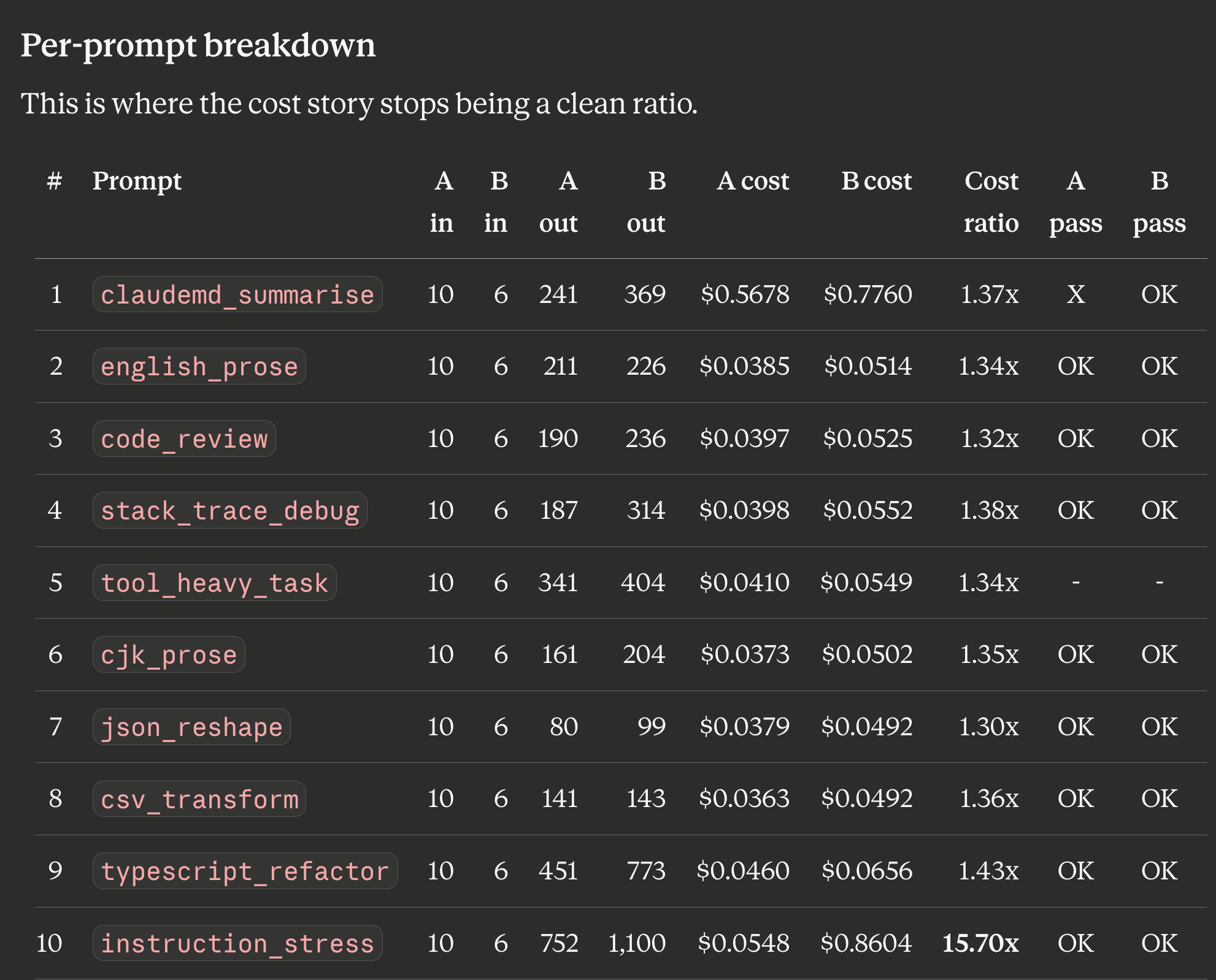
Prompts 2 through 9 all land in a narrow 1.30x to 1.43x cost ratio. That’s boring. It’s also the shape you want: per-turn cache reads dominate billing once the system prompt is warm, and both models are reading the same warm cache at the same $0.50/M rate, so the per-turn ratio ends up close to the output-token ratio (1.43x on aggregate).
Prompt 1 (claudemd_summarise) carries the first-turn cache write. On both sides it’s the single biggest cost line. 4.7 costs 1.37x here because its system-prompt encoding is 1.37x larger.
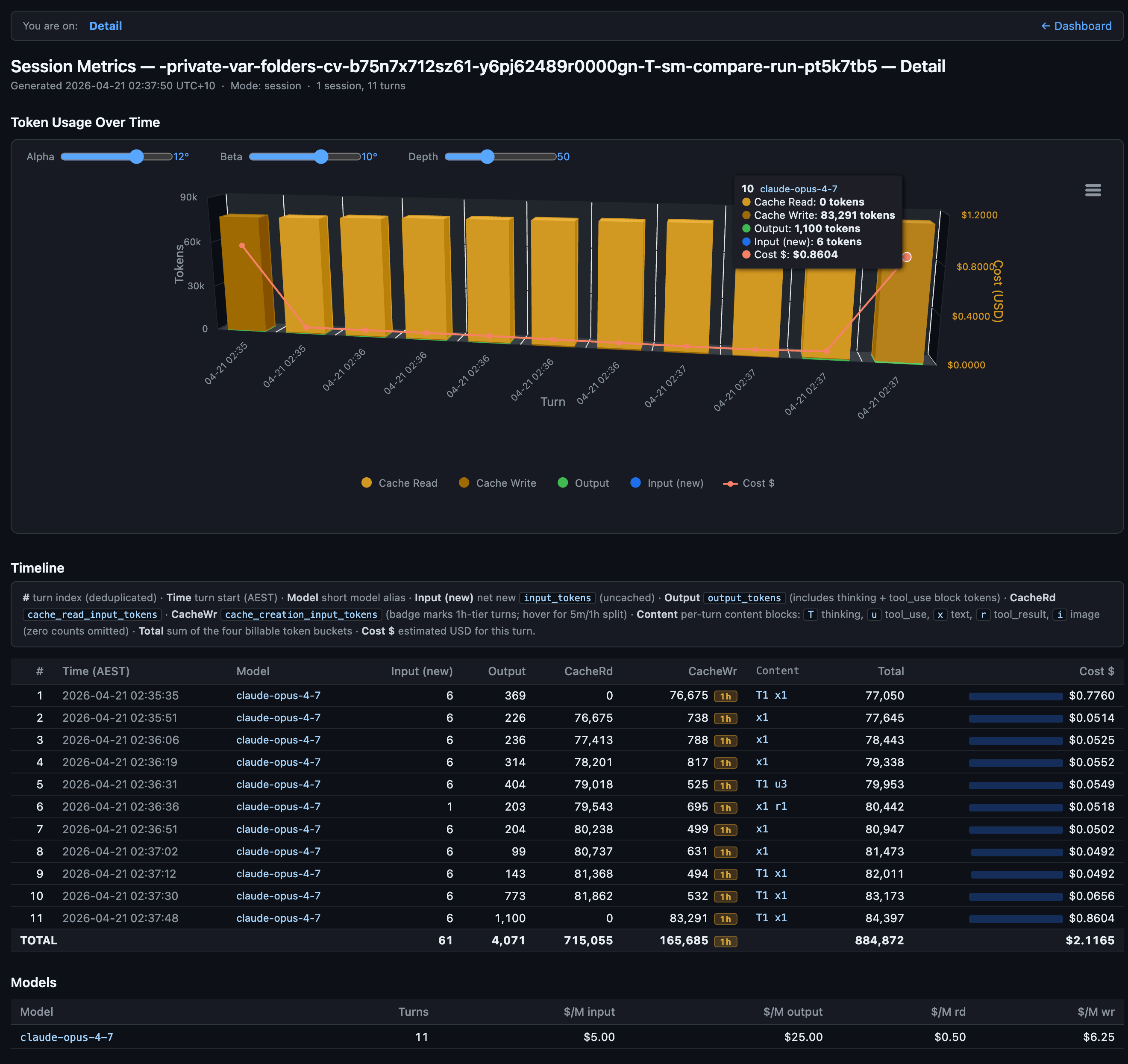
Prompt 10 (instruction_stress) is the outlier. One turn on Opus 4.7 [1m] cost $0.8604. The same turn on Opus 4.6 [1m] cost $0.0548. That single turn accounts for roughly $0.81 of the $1.14 total cost delta between the two sides. Over 70% of the aggregate 2.17x ratio is this one prompt.
Looking at the Side B detail export, turn 11 on Opus 4.7 reports zero cache reads and a fresh cache write of 83,291 tokens. The previous turn had healthy cache reads. In plain English: something about how instruction_stress (a long, deliberately contradictory instruction-following test) got processed made Opus 4.7 invalidate its warm cache on the final turn and pay to re-encode the entire system prompt from scratch. Opus 4.6 handled the same prompt without any cache disruption. This is exactly the kind of hidden cost the skill is built to surface.
If I trim that one turn from both sides, the 2.17x aggregate collapses to roughly 1.36x ($1.2561 / $0.9220), right in line with the boring middle-of-the-table ratio. That’s the number I’d quote if I were choosing between these models for my own “normal” Claude Code session shape.
But I’m not going to trim it, because the whole point of running a controlled suite is to catch pathological turns. One blow-up turn per session is realistic.
Extended thinking usage
“Extended thinking” is Claude’s hidden reasoning step: before it answers you, the model spends tokens on a private scratch-pad that you never see but still pay for. Opus 4.6 at effort high used that scratch-pad on 10 of 11 turns (90.9%). Opus 4.7 at effort xhigh used it on only 5 of 11 turns (45.5%). More thinking usually means more cost, so you’d expect 4.7 to have thought harder. It didn’t.
Opus 4.7’s xhigh is adaptive thinking. The model decides per turn whether to think at all, and how long to think for, instead of spending a fixed budget every time. On the 5 prompts where 4.7 skipped thinking entirely, it still beat 4.6 (which thought on every turn) on IFEval. That is the gain you’re paying for. The 11.1 percentage-point compliance improvement is not coming from “4.7 thinks more”. It’s coming from “4.7 thinks more selectively and writes longer when it does”.
Claude Opus 4.7 adaptive thinking exported HTML
Claude Opus 4.6 extended thinking exported HTML
Decision framework
So what do you do with a 2.17x ratio and a +11.1 pp gain? The skill ships with a canonical decision table:

My matched bucket is very-expensive. 2.17x is prohibitive for a blanket switch, regardless of the +11.1 pp IFEval gain. The framework’s prescription is what I’d do anyway: keep Opus 4.6 [1m] as the default for normal work, route to Opus 4.7 [1m] only for tasks where a +11.1 pp compliance improvement is worth a 2.17x cost.
For me, that’s a narrow set. Code review on high-stakes diffs. Final-pass refactors where correctness trumps iteration speed. Anything where instruction adherence is the gating factor, not generation time.

Caveats
A handful of things to keep in mind before generalizing this to your own workloads.
Single run. Each prompt runs once per side. Tokenizer ratios are usually stable to within a couple of percent across repeats, but one-off captures can swing 10% or so on output-token ratios. Multi-trial support is on the skill’s roadmap.
Same-tier pairing. Both sides are [1m]. Running default tier vs [1m] would conflate the tokenizer change with the context-window change, and the report would fire the context-tier-mismatch advisory. If you want a pure tokenizer-only read, keep tiers symmetric.
Canonical suite, not real work. The 10 prompts cover the content shapes the upstream Anthropic tokenizer write-up measured. My actual daily dev work is skewed heavily toward code-review and codebase-Q&A shapes, not English prose or CJK. On my real workload the ratio is probably closer to 1.30x to 1.50x than 2.17x, once the instruction_stress blow-up is amortized across many more turns. Add your own prompts to the suite and re-run if you want a true workload match.
Cache warmth between sides. Side B ran 14 seconds after Side A finished. Both sides start with a cold system-prompt cache, but the enclosing environment (disk cache, OS page cache, Anthropic edge cache) is slightly warmer on B. That shows up as B’s cache hit ratio being 9.3 pp lower (bigger first-turn write, proportionally fewer reads). Still inside the skill’s 10 pp drift advisory, but it’s a real asymmetry.
Claude Code system prompt drifts over time. If you re-run this comparison in three months against newer Claude Code builds, some of the ratio change will be system-prompt evolution, not model change. The skill tags the Claude Code version it observed in the per-session detail export so you can tell.
Subscription allowance was raised to match. Anthropic lifted paid-tier limits when Opus 4.7 shipped. Boris Cherny, Claude Code lead at Anthropic, posted on Threads: “We’ve increased limits for all subscribers to make up for the increased token usage.” The 2.17x dollar ratio above is API-equivalent billing from the skill and is unaffected. On a Pro / Max / Team / Enterprise subscription the headroom story is softer than the raw token growth suggests. If your usage feels heavier after upgrading, that is expected; the allowance went up with it. I wrote up the fuller setup guidance in Six Things to Change in Your Claude Code Setup After Upgrading to Opus 4.7.
Reproduce it yourself
Two prerequisites: an active Claude subscription (Pro / Max / Team / Enterprise) and claude --version returning a current build on your PATH. The skill uses claude -p headless under the hood; it inherits your subscription auth and rate limits, no API key involved.
Install the plugin:
/plugin marketplace add centminmod/claude-plugins
/plugin install session-metrics@centminmod
/reload-pluginsRun the comparison:
/session-metrics compare-run claude-opus-4-6[1m] claude-opus-4-7[1m] --compare-run-effort high xhighOutput drops into a timestamped subdirectory under your current project’s exports/session-metrics/ folder: a compare report (markdown + HTML), per-session dashboards (markdown + dashboard HTML + detail HTML), and an _analysis.md scaffold with TODO placeholders for writing up the results. That scaffold is what I filled in to write this post.
If claude -p isn’t available on the machine where you want to analyse the numbers (CI container, locked-down workstation), use --compare-prep to print the manual capture protocol, run the 10 prompts by hand in two interactive sessions, then feed the resulting JSONLs to --compare. Same report, more keystrokes.
What I learned
The aggregate ratio lies about the middle. 2.17x is the headline, but 8 of 10 prompts cost between 1.30x and 1.43x. One turn drove the outlier. If you only read the summary row of a compare report, you miss the shape of the distribution and the specific prompt that cost you real money.
Adaptive thinking changes what you pay for. Opus 4.7 xhigh thinks less often than Opus 4.6 high does, and still wins on compliance. “Fewer thinking tokens, better outputs” is the correct picture for the newer model. It also means per-turn cost is less predictable, because the model chooses.
Cache behaviour is part of the model. The instruction_stress cache invalidation on 4.7 wasn’t a Claude Code bug or my fault. It’s something about how that specific prompt shape interacts with 4.7’s cache discipline on the 1M tier. That’s the kind of thing no benchmark blog post will tell you. You find it by running the comparison on your own machine and looking at the per-turn table.
“Stay or use selectively” is the right answer more often than people admit. The plugin-marketplace release post had me installing new things. This post has me not installing new things, because the data says so. Both are legitimate builder outcomes.
What’s next
I want to run the same comparison on claude-opus-4-6 vs claude-opus-4-6[1m] to isolate the pure context-tier delta on a single model. And then claude-opus-4-7 vs claude-opus-4-7[1m] for 4.7. That’s two more compare-run invocations and should give me a clean three-way decomposition: tokenizer change, tier change, and effort-level change, each priced separately.
I’m also adding two prompts to the canonical suite that reflect my actual daily workload: a codebase-Q&A prompt with a real repo tree in context, and a mid-refactor diff-review prompt. The canonical 10 are a useful neutral baseline. They are not my work.
If you’re interested in practical AI building for web apps, developer workflows, and infrastructure, subscribe for future posts. You can also follow my shorter updates on Threads (@george_sl_liu) and Bluesky (@georgesl.bsky.social) or subscribe and follow along.