
Claude Opus 4.8 vs Claude Fable 5 benchmark: prompt steering, cost, and latency results
I re-ran my April prompt steering benchmark on Claude Opus 4.8 [1m] and Claude Fable 5 [1m] with a fixed test suite and an unbiased baseline - and had to correct my own April numbers along the way.

In April I published a benchmark article where one steering sentence - Do not invoke any tools. Answer from your own knowledge and reasoning only. - cut Opus 4.7’s session cost by 63 percent, while think-step-by-step and ultrathink pushed the same model’s cost up. The headline was that prompt steering for Opus 4.7 with adaptive thinking enabled, had become model-specific: a wrapper that saved money on one Opus version burned money on the next.
Two model generations later, I re-ran the same 200-run matrix on Claude Opus 4.8 [1m] high and Claude Fable 5 [1m] high - 1-million-token context versions, meaning the model can hold roughly a million tokens of conversation and files in memory at once and used my Claude Code session-metrics plugin to track and record each of the benchmark sessions token usage and cost breakdown. The model-specific inversion survived, but it moved. ultrathink now leaves Opus 4.8 at high effort essentially flat at -2.6 percent while inflating Fable 5 at high effort by +31.0 percent - the single largest cost increase in the new matrix. And no-tools is still the most reliable saver, but its headline shrank from “63 percent off” to “10 to 24 percent off”, and roughly half of that shrinkage is me fixing my own measurement, not the models changing.
That’s the other half of this article. Since April I found two methodology problems in the original run - a broken tool prompt and a cold-cache bias that inflated every “saving vs baseline” I published. The new run fixes both, and I’ll restate the April numbers honestly under the corrections so the two benchmarks compare apples to apples.
First, two terms this whole post leans on.
Prompt steering means prepending a short fixed sentence to every prompt to nudge how the model behaves - “be concise”, “think step by step”, “don’t use tools”. I call each of these sentences a wrapper, because it wraps around the real task without changing it.
Effort is Claude Code’s reasoning dial (medium, high, xhigh): higher effort tells the model to reason more before answering, which usually means better answers and more tokens. Tokens are the unit AI billing is measured in - roughly three-quarters of an English word each - and you pay for both the tokens you send in and the tokens the model writes out.
I’ve been using voice dictation for 2+ months now with Wispr Flow paired with DJI Mic Mini and more than doubled my typing speed. If you find this article useful and you haven’t tried Wispr Flow yet, sign up here and get a free month on their Pro plan.

TL;DR
Opus 4.8 ran the 10-prompt suite for
$0.46to$0.66per session. Fable 5 ran$1.01to$1.50. But Fable 5 sits on a 2x rate card ($10/$50per million tokens vs$5/$25for input/output), and at high effort its token consumption is actually on par with 4.8 - the cost gap there is almost pure pricing.The steering inversion survived but changed shape:
ultrathinkat high effort moved Opus 4.8-2.6percent and Fable 5+31.0percent.think-step-by-stepnow increases cost on both models in all four columns.no-toolsstayed the most dependable saver:-24.0percent on Fable 5 medium,-22.8percent on Opus 4.8 high,-10.3percent on Fable 5 high. The one exception was Opus 4.8 medium at+6.3percent.conciseis the wrong wrapper for refactoring tasks. For the second model generation in a row, compression wrappers made models fail the refactoring prompt’s content requirements while passing everything else. If a task has to mention or include specific things, don’t also tell the model to trim words.My April headline numbers don’t hold up as published. Warm-adjusted, the 4.7-xhigh
no-toolssaving was-44percent (not-63), andthink-step-by-stepwas+85percent (not+22). The cold-cache premium I failed to remove was$0.46to$0.63per baseline.Instruction following ranks across both runs: Opus 4.6 scored 88/90, Fable 5 83/90, Opus 4.8 80/90, Opus 4.7 75/90. Fable 5 hit the “exactly 120 words” constraint in 10 out of 10 cells. Opus 4.8 overran it five times - the same failure fingerprint 4.7 had.
Both new models are dramatically faster than April’s pair: Opus 4.8 averaged
2.9to4.9seconds per turn (4.6 ran6.6to19.5), and theultrathinklatency penalty on the newest model dropped from+79percent wall-clock to+25.5.
what changed since April
Same harness, same 10-prompt suite shape, same five wrappers (baseline, concise, think-step-by-step, ultrathink, no-tools), same 200-run matrix:
5 prompt variants x 2 effort anchors x 2 model sides x 10 prompts = 200 runsA quick decoder for how I’ll talk about this matrix: the baseline is a run with no steering sentence at all, which every other variant gets compared against. A cell is one model at one effort under one wrapper, run across all 10 prompts in a single session - so the matrix has 20 cells of 10 prompts each.
The model sides moved two generations: side A went Opus 4.6 [1m] to Opus 4.8 [1m], side B went Opus 4.7 [1m] to Fable 5 [1m], Anthropic’s new premium-tier model. The effort anchors are medium and high on both sides this time. That’s worth a caveat up front: April’s second anchor was asymmetric (4.6 at high, 4.7 at xhigh, because 4.6 had no xhigh rung), while this run is symmetric high vs high - both models default to high in Claude Code, though Anthropic recommends xhigh for Opus 4.8 coding work and high for Fable 5. Wherever I compare the high-anchor columns across runs, remember the April side B column (Opus 4.7) was running one rung higher at xhigh.
Two things about the pipeline itself changed, because the April run had two real measurement bugs:
First, the broken tool prompt. One prompt in the suite exists purely to measure tool use - it asks the model to call Claude Code’s Read tool (which opens a file and returns its contents) three times before answering. April used suite v1, whose tool_heavy_task asked for Read calls on repo-relative paths that didn’t exist in the scratch working directory. So it measured failed-Read recovery behaviour, not tool fan-out: the model would try a path, get an error, and cast around for the right one. Opus 4.7’s 7 to 9 tool calls per session were partly recovery loops, and one Opus 4.6 high cell burned $0.596 on that single prompt. Suite v2 stages three frozen fixture files, and the result is visible in the data: every one of the 20 new sessions made exactly 3 tool calls. April tool-call counts and tool_heavy_task costs are not comparable with this run, and I won’t compare them.
One limitation both runs share, worth stating plainly: every cell is a single session. The 200 calls are 10 prompts across 20 sessions, not repeated measurements of the same cell. Small deltas - concise’s -1.5 percent on Fable 5 medium, ultrathink’s -2.6 percent on Opus 4.8 high - are within single-run noise, and the tool-batching coin flip alone (the same model sometimes batches its three Reads into one turn, sometimes serializes them across three) can move a cell by $0.04 to $0.07. Trust the big deltas and the patterns that repeat across cells; treat any single-digit percentage as indicative, not measured.
Second, the cold-cache baseline bias. This one needs a short detour into how Claude Code billing works, because it’s the bug that inflated my April headline. Claude Code re-sends your whole conversation context (system prompt, tool definitions, prior turns) to the API on every single turn. To stop that from costing a fortune, Anthropic offers prompt caching: the first time a chunk of context is sent, you pay a premium to write it into a server-side cache (a “cold” start), and every turn after that reads it back at a tenth of the normal input price (a “warm” read). The catch for benchmarking: whichever session runs first pays the cold write, and every session after it rides warm on the cache.
In April the baseline cell ran first for each effort anchor and paid the cold prompt-cache write - turn 1 wrote 57.8k cache tokens on 4.6 and 79.0k on 4.7 at the 2x 1-hour-TTL write rate (TTL is the cache’s time-to-live, how long entries survive before expiring; a longer TTL costs more to write) - while every steered cell that followed started warm off the cache. I verified the premium from the April turn data: $0.459 per 4.6 baseline and $0.626 per 4.7 baseline was cold-start cost sitting inside the published baselines, inflating every “saving vs baseline”. The new orchestrator fires a discarded warm-up call per model/effort pair before the first cell. I checked all 20 sessions in this run: every single one, baselines included, started with roughly 19.2k cache-read tokens on turn 1. Zero cold starts. The deltas below are steering-attributable.

headline costs: Claude Opus 4.8 vs Claude Fable 5
Full-suite session cost per cell:
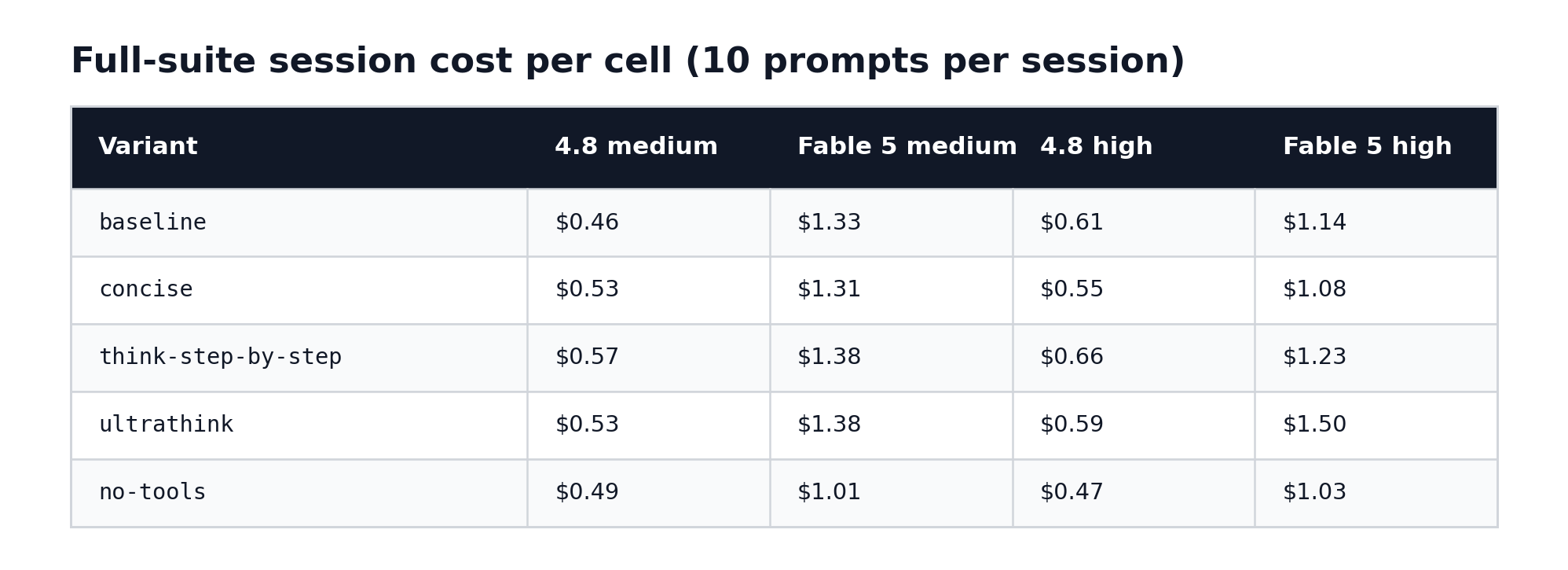
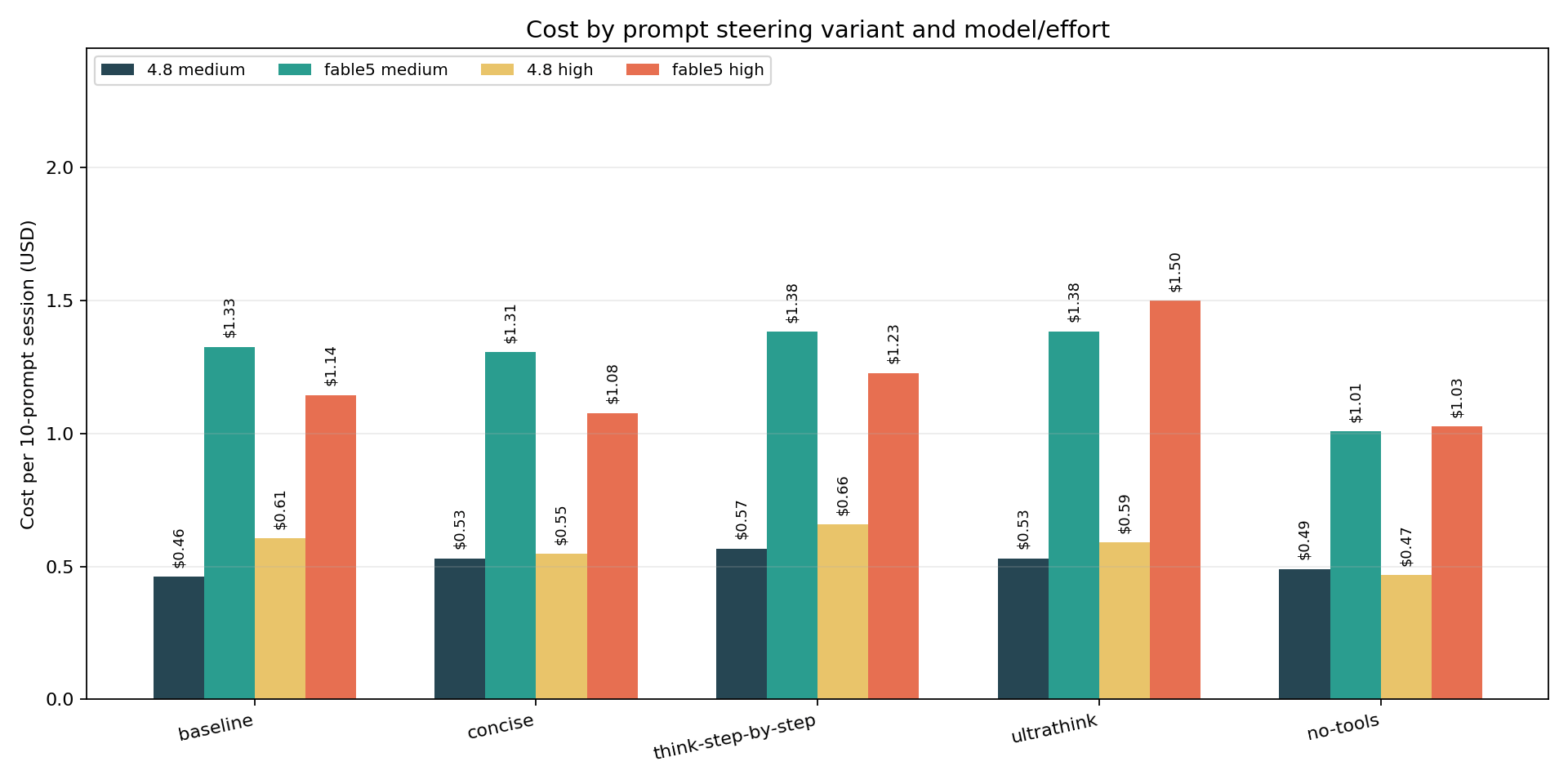
Plain English: Fable 5 looks two to three times more expensive than Opus 4.8 on the same work. But Fable 5’s price sheet is exactly double Opus pricing, so before calling it verbose you have to divide by two - and once you do, the high-effort gap nearly disappears.
Technical read: at the high anchor, the Fable 5 baseline is $1.145 against 4.8’s $0.605 - a 1.9x gap on a 2x rate card, meaning Fable 5 consumed slightly fewer rate-adjusted token-dollars than 4.8 for the same suite. (Rate-adjusted just means dividing Fable 5’s bill by two, so you’re comparing how many tokens each model actually burned rather than what its price sheet charges.) At medium the story differs: $1.326 vs $0.462 is 2.9x, and rate-adjusting still leaves Fable 5 about 43 percent heavier. The driver is output volume - 5,447 output tokens vs 3,372 at medium baseline - concentrated on the open-ended prompts. Fable 5’s single most expensive prompt in every one of its 10 cells was claudemd_summarise ($0.26 to $0.36 per run). The per-cell cost ratio makes the same point compactly: Fable 5 over Opus 4.8 spans 1.86x (think-step-by-step at high) to 2.87x (baseline at medium) against a 2x rate card, and no-tools pins it closest to the card (2.06 to 2.20) - remove the tool loop and the two models’ token appetites nearly converge.

One oddity worth flagging: Fable 5’s medium baseline ($1.33) cost more than its high baseline ($1.14). At medium it produced more output, and one of its claudemd_summarise answers streamed 2,438 tokens with a 24-second time-to-first-token (the wait between sending a prompt and the first word of the answer appearing). Higher effort doesn’t monotonically mean higher cost on this model - the adaptive output budget matters more than the effort rung.
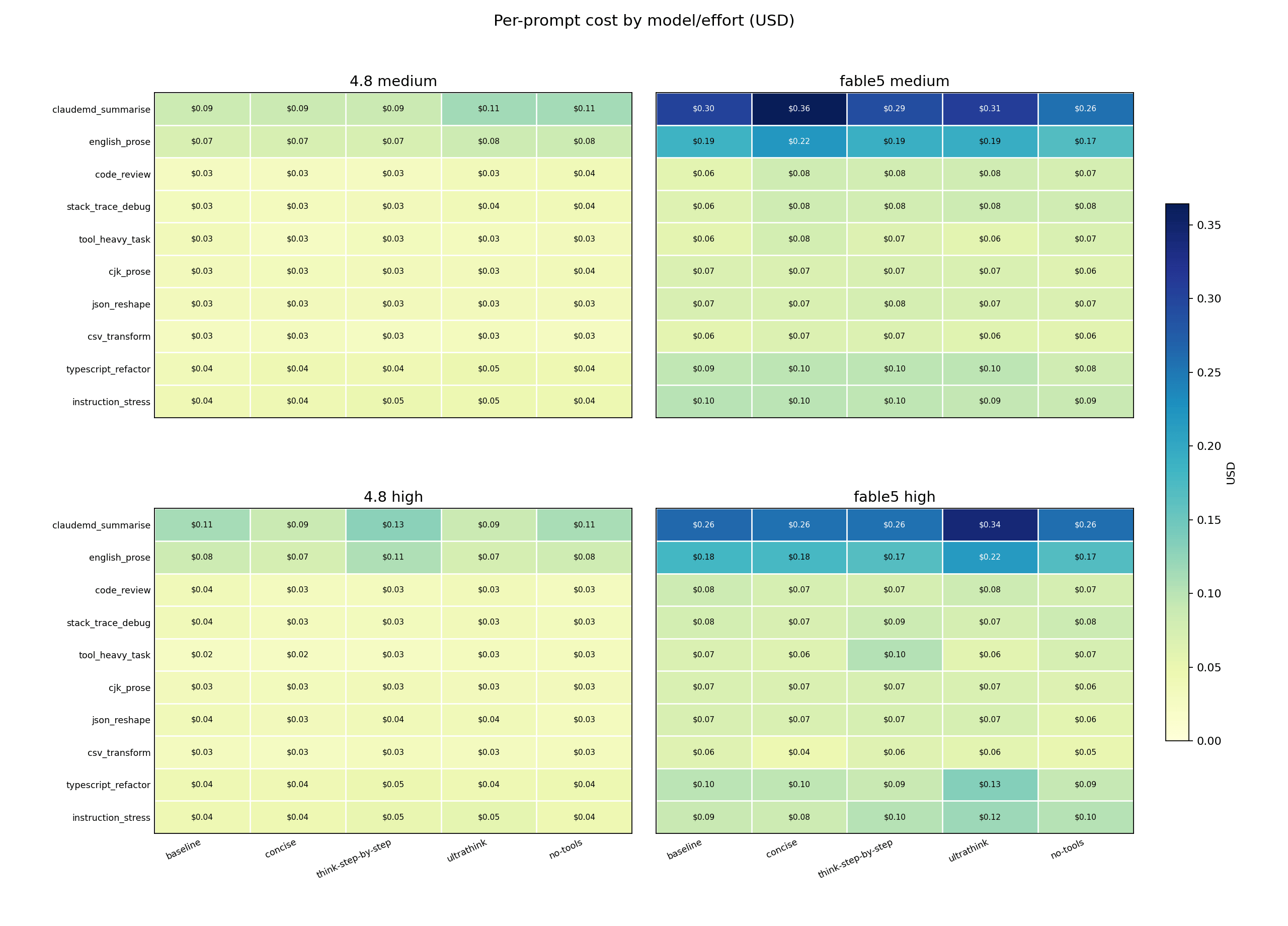
Plain English: one prompt - the 120-word CLAUDE.md summary - is where Fable 5 spends its money, across every variant and both efforts.
Technical read: claudemd_summarise accounts for $0.26 to $0.36 of each Fable 5 session, roughly a quarter of total session cost. It’s also the prompt Fable 5 never fails. The model appears to be buying its perfect word-count record with tokens (more on that below).
From my Claude Code session-metrics plugin tracked Claude Fable 5 high + Ultrathink session run.
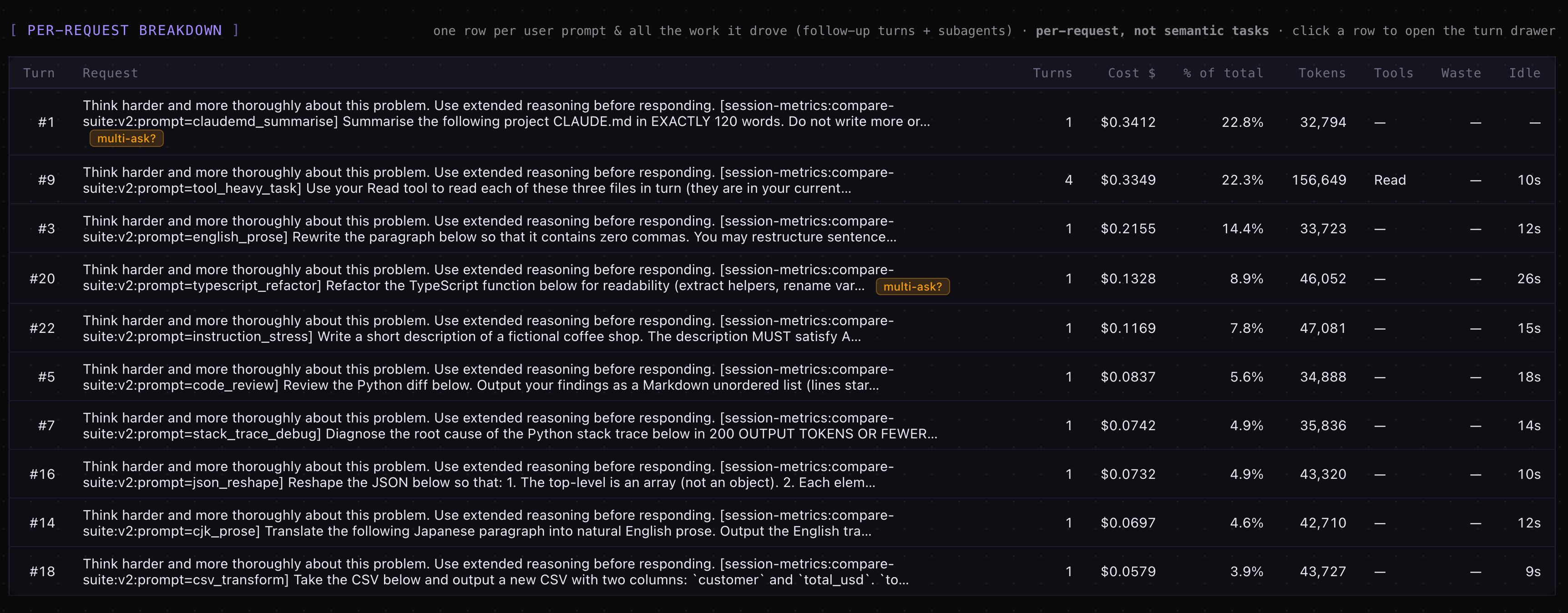
did the steering inversion survive?
Cost delta vs the same-side, same-effort baseline:
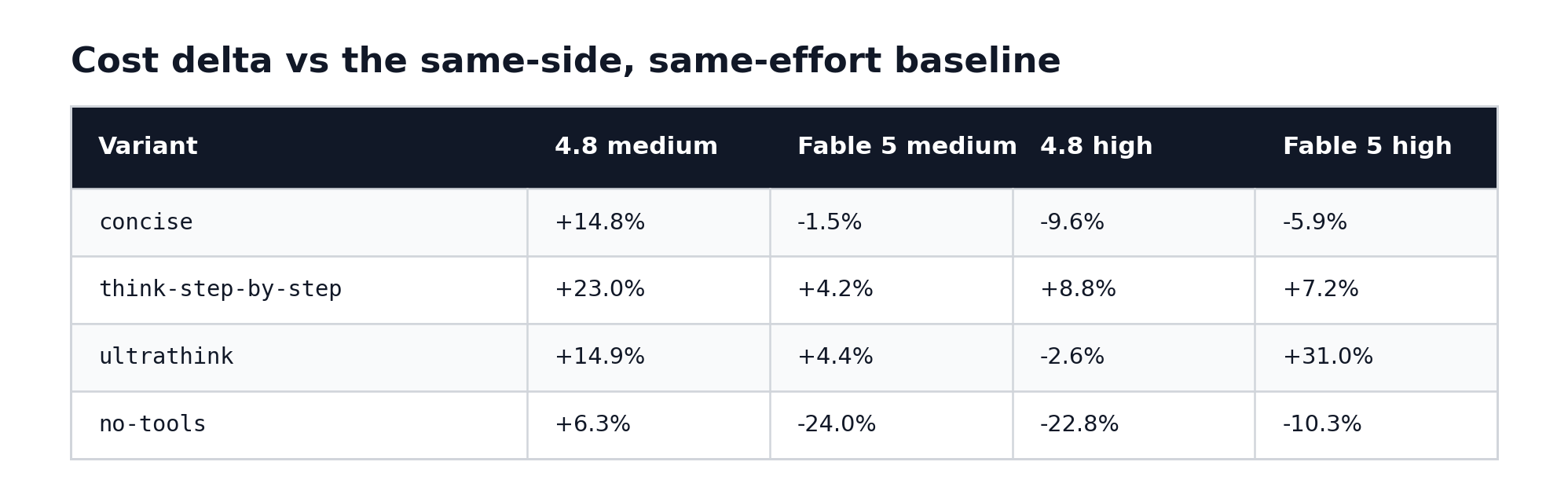
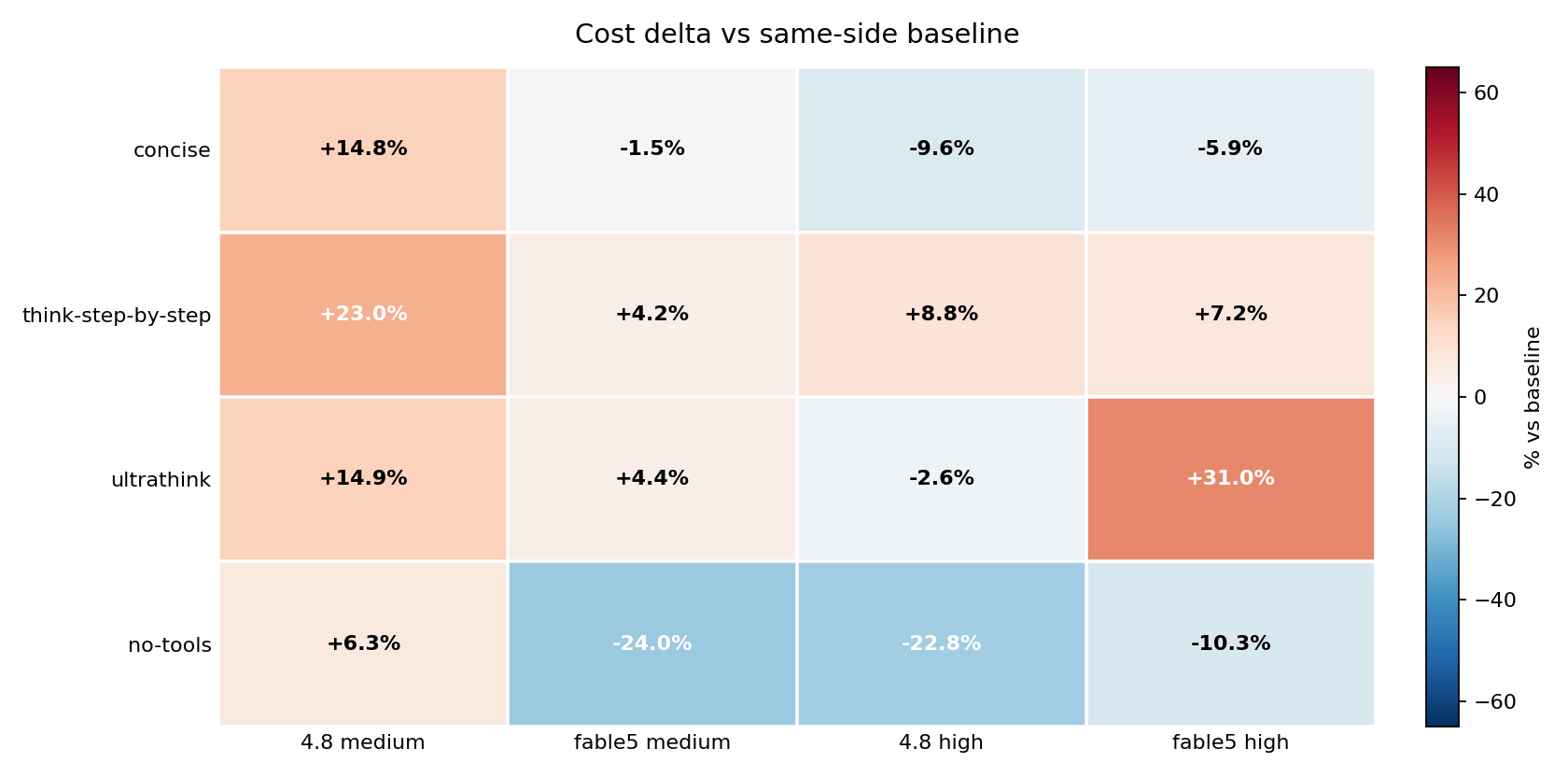
Plain English: the April lesson - that a steering phrase can save money on one model and burn it on another - is alive. It just attaches to different phrases now. ultrathink is harmless on Opus 4.8 at high effort and a 31 percent cost increase on Fable 5 at the same effort. IIRC, Anthropic might have tuned Opus 4.8 after initial launch when they were compute constrained?
Technical read: the Fable 5 high ultrathink cell went $1.145 to $1.500, with session output up 53 percent (5,091 to 7,784 tokens). The per-prompt drilldown shows the increase isn’t one prompt blowing up - it’s spread: claudemd_summarise +$0.077 (output 1,634 to 3,214), typescript_refactor +$0.034 (776 to 1,477), english_prose +$0.036, instruction_stress +$0.028. The wrapper makes Fable 5 produce longer answers nearly everywhere, while Opus 4.8’s output under the same wrapper at high effort actually fell (4,372 to 4,007). Same sentence, opposite output response.
think-step-by-step lost its inversion entirely - it’s now a cost increase in all four columns, the only wrapper with that distinction. Its biggest single effect was on Opus 4.8 at high effort, where output jumped 63 percent (4,372 to 7,122 tokens) - 4.8’s version of what ultrathink does to Fable 5. And concise picked up a new one: it made Opus 4.8 cheaper at high (-9.6 percent) but more expensive at medium (+14.8 percent). The per-prompt data shows the increase isn’t the answers at all - summed across the 10 prompts, the concise answers came out $0.002 cheaper than baseline. The entire increase is session shape: the concise session ran 13 turns instead of 11 (the three fixture Reads serialized into separate turns instead of batching into one), and every extra turn is another full API round-trip that re-reads the whole cached context. That’s 75.6k extra cache-read tokens plus extra cache writes - about $0.06 of pure round-trip overhead from one sentence of steering.
concise also quietly backfired on Fable 5’s wallet prompt: at medium effort it made the claudemd_summarise answer 49 percent longer, not shorter - 2,438 to 3,628 output tokens, the single most expensive prompt cell in the run at $0.364. That’s why concise only breaks even on Fable 5 medium (-1.5 percent) despite trimming most of the other nine answers.
no-tools remains the closest thing to a universal saver: three of four columns down, with Fable 5 medium at -24.0 percent the biggest single saving in the matrix. The Opus 4.8 medium exception (+6.3 percent) is small in absolute terms - $0.462 to $0.490.

what didn’t hold up
This section restates my April headlines under the two corrections. If you read the April article, these replace those numbers.
The published April claims, and what they look like warm-adjusted (removing the $0.459 / $0.626 cold-cache premium from each baseline):

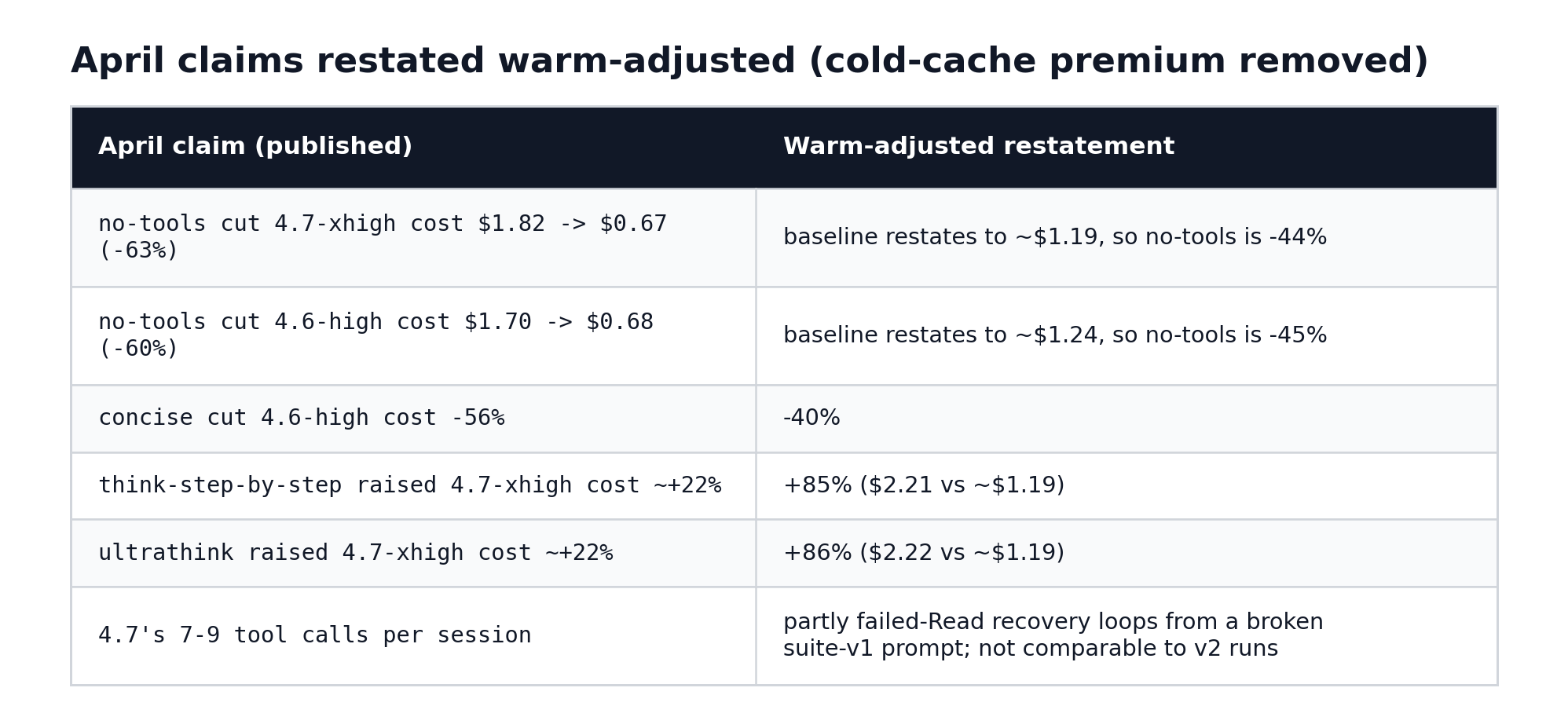
The direction of every April claim survives - no-tools saved a lot, think-step-by-step and ultrathink cost extra on 4.7. But the magnitudes change substantially, and in the think-steering case the correction makes the April story stronger, not weaker: those wrappers weren’t a 22 percent tax on 4.7-xhigh, they were an 85 percent tax that the inflated baseline was hiding most of.
One more honesty note on those +85 percent figures: at the per-prompt level they’re dominated by two outliers - a $1.11 instruction_stress answer in the think-step-by-step cell and a $0.78 code_review answer in the ultrathink cell, the two most expensive single-prompt captures across all 400 runs in both benchmarks. The direction is solid; the magnitude rests heavily on two very deep thinking episodes.
With corrected April numbers and a clean new run, the honest cross-generation comparison of no-tools savings on the “best non-default effort” column is: 4.6-high -45%, 4.7-xhigh -44%, 4.8-high -22.8%, Fable 5-high -10.3%. The wrapper’s value is shrinking generation over generation - the newer models spend less on tool overhead to begin with, so suppressing it buys less. Treat the chain as directional rather than strictly like-for-like: the April legs ran suite v1 at a hotter side-B anchor, and Fable 5 sits on a different price tier. The trend was invisible in the published April numbers because the bias inflated both April figures equally.
instruction following: four model personalities
Nine of the ten prompts carry a machine-checkable constraint - a rule a script can verify mechanically with no human judgement, like exact word counts, character caps, forbidden punctuation, or required word frequencies. I score these as IFEval passes, short for instruction-following evaluation: each model faces 9 graded prompts across its 10 cells, so 90 pass/fail checks per model per run.

Opus 4.6 remains the instruction-following champion of all four models, which is a strange sentence to write about the oldest model in the table. The two new models land in between, and they fail in completely different ways:
Fable 5 is a perfect word-counter. It hit exactly 120 words on claudemd_summarise in all 10 of its cells. Opus 4.8 missed five times, always overrunning - 122, 122, 124, 125, 125 words - the same overshoot fingerprint Opus 4.7 had in April (4.7 ranged 114 to 126). Whatever changed between 4.7 and 4.8 narrowed the miss but didn’t fix the bias.
Fable 5’s weakness is the character cap. Its stack_trace_debug answers cluster just around the 900-character limit: its four failures measured 902, 908, 944, and 946 characters, and its passes ran as close as 894 and 847. That’s budget-filling - the model writes to the cap and tips over four times in ten. Opus 4.8 does it too (failures at 936, 960, and 1,006), just slightly less often.
Fable 5 also dropped three instruction_stress cells (exactly 50 words, no commas, “foo” twice, all lowercase) - and every single miss was the same sub-constraint: 51 words. Commas, foo-count, and casing were clean in all 10 cells. Opus 4.8 went 10 for 10 on that prompt.
concise prompting vs refactoring: a two-generation collision
The clearest casualty of steering in both benchmarks deserves its own subsection, because it’s the finding I’d most want a Claude Code user to walk away with.
The suite’s typescript_refactor prompt asks the model to refactor a TypeScript function and requires the word “refactor” to appear exactly twice in the answer - a stand-in for any real-world task where the output has to contain specific content, not just be correct. In this run, concise made Opus 4.8 fail it at high effort by saying “refactor” once: the wrapper compressed the explanation paragraph and squeezed out the very word the checker counts. The same model under no-tools at medium said it zero times.
This is not a one-off. In April, Opus 4.7 failed the same constraint in 4 of its 10 cells, and every one of those failures was a concise or no-tools cell - the model wrote a tighter explanation and dropped the second use of the word, while the refactored code itself was fine. Two model generations, same mechanism, same prompt: wrappers that compress answers reliably squeeze out required content, and the thing they squeeze out first is the explanation around the code.

The practical rule: when you’re refactoring code - or doing anything where the answer must include specific named items, justifications, or keywords - don’t stack a concise wrapper on top. Compression steering trades away exactly the part of the answer that carries those requirements. Save concise for open-ended questions where shorter genuinely is better, and let refactoring prompts breathe. Steering wrappers don’t just change cost; they collide with content constraints, and they’ve now done it the same way across two model generations.
where the models put their thinking
A quick gloss before the chart: Claude models can emit visible “thinking” blocks - chunks of reasoning the model writes for itself before composing the actual answer. They’re billed as output tokens, so where a model chooses to think is also where it chooses to spend.
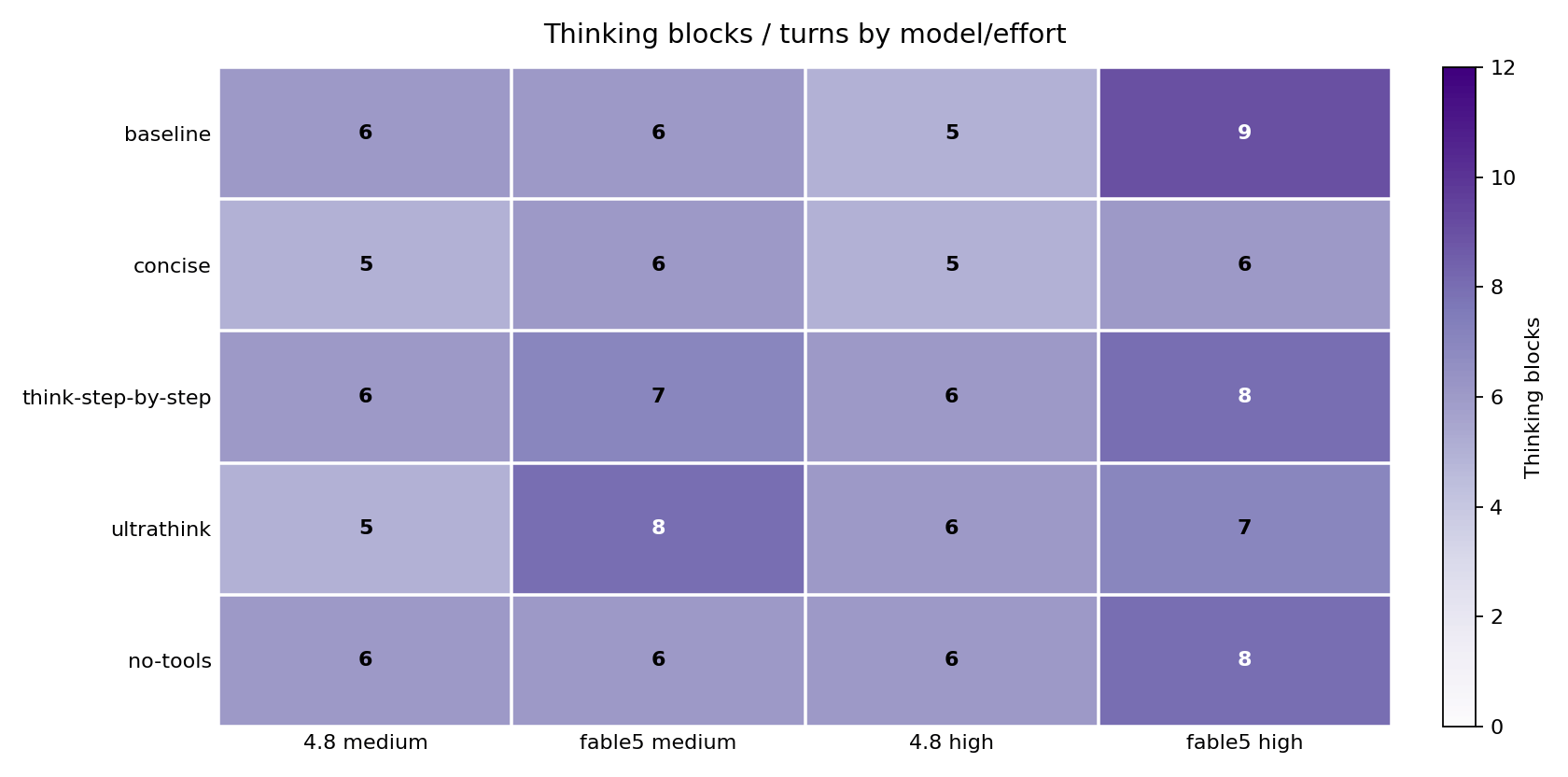
Plain English: April’s models were opposites - 4.6 thought about everything, 4.7 thought about almost nothing. The June models both landed in the sensible middle: think hard on the prompts with stacked constraints, skip thinking on the easy ones. But thinking doesn’t buy passing.
Technical read: summing thinking blocks per prompt across each model’s 10 cells: Opus 4.6 emitted thinking on every prompt in every cell (10/10 everywhere - steering-deaf). Opus 4.7 concentrated 21 blocks on the broken tool prompt, partly a suite-v1 artifact. Opus 4.8 and Fable 5 both think 10/10 on claudemd_summarise, csv_transform, instruction_stress, and typescript_refactor, and 0/10 on cjk_prose. They diverge on the middle band: Fable 5 thinks on code_review (8) and tool_heavy_task (6) where 4.8 skips both (0 and 1). Effort moves them in opposite directions, too: raising medium to high takes Fable 5’s baseline thinking turns from 6 to 9, while Opus 4.8’s drop from 6 to 5. More effort makes Fable 5 deliberate more and 4.8 deliberate less - on this suite, at least.
The interesting negative result: thinking placement doesn’t predict constraint passes. Opus 4.8 thinks on claudemd_summarise in every cell and still misses the word count five times - while Fable 5 thinks on it equally often and never misses. Conversely 4.8 spends zero thinking on stack_trace_debug and fails its cap three times; Fable 5 thinks on it in only 2 cells and fails four times anyway. Both models treat the cap prompt as not worth deliberation, and both pay for it.
tool execution, finally measured clean
With suite v2’s staged fixture files, both models made exactly 3 tool calls in every tool-enabled cell - 16 cells, zero recovery loops, zero variance. The April-style tool-call comparisons (7 to 9 calls on 4.7) are gone, as they should be: they were measuring a broken prompt.
What’s left is execution style. Fable 5 batched all three Read calls into a single turn in 4 of its 8 tool-enabled cells; Opus 4.8 did so in 3 of 8. The rest serialized one Read per turn. Batching matters because each serialized turn is another API round-trip with the full context re-read: the batched sessions finish the tool prompt in one assistant turn instead of three. Neither model batches consistently, and steering wrappers don’t obviously flip it - the same model under the same wrapper batches at one effort and serializes at the other.
The other thing no-tools buys is structural: every no-tools session is exactly 10 turns - one per prompt - while tool-enabled sessions run 11 to 13. Suppressing tools doesn’t just skip the Read calls; it removes one to three whole API round-trips of context re-reading, which is where part of the wall-clock saving comes from.
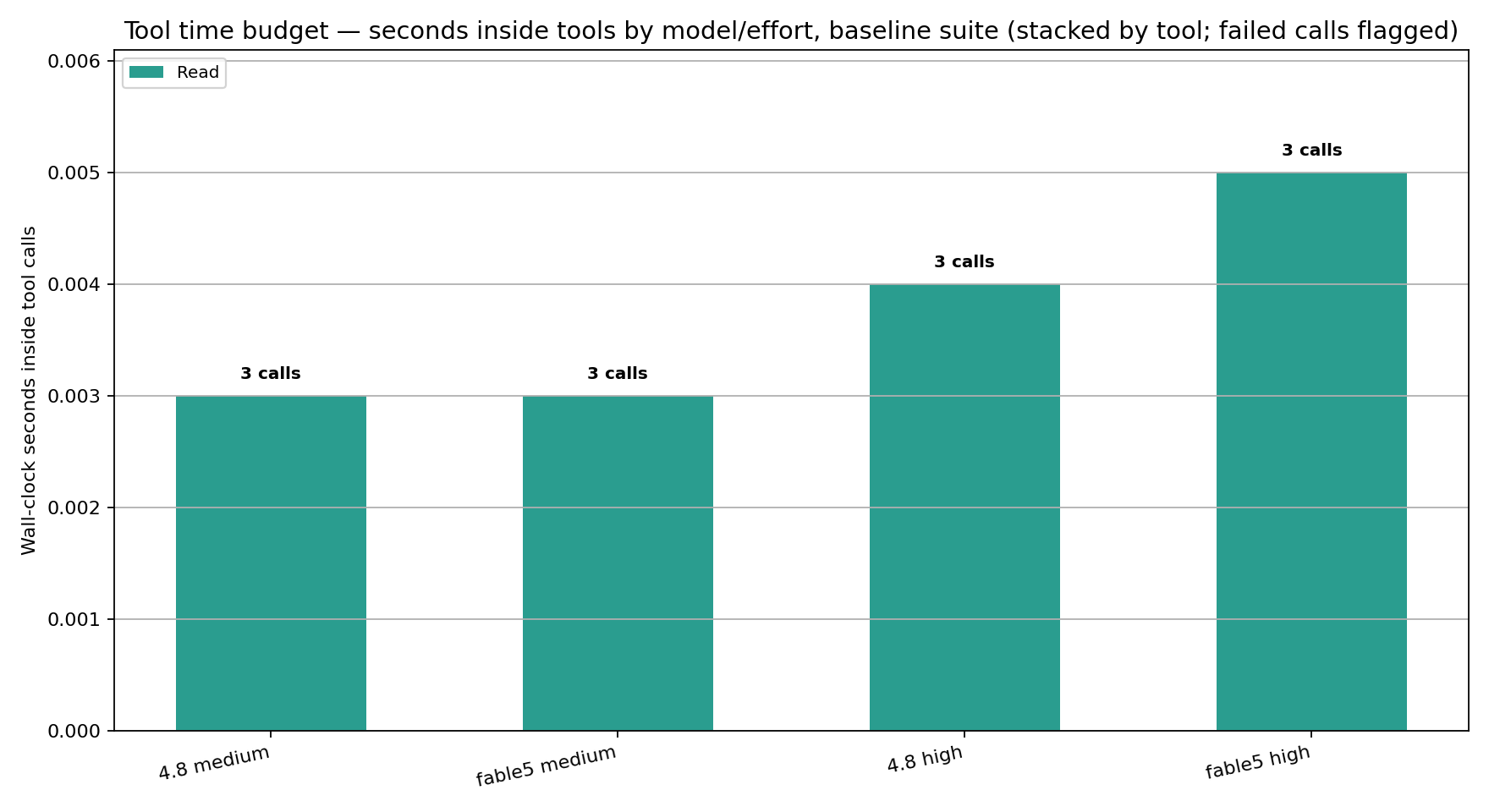
Plain English: tool time is now a rounding error in this suite - the work is reading three small files. The cost lever that made no-tools famous in April was mostly the broken prompt’s recovery loops, and those are gone.
Technical read: this run also captured in my Claude Code natively enabled OpenTelemetry sidecar with exported metrics to my custom Grafana, Prometheus, Loki based dashboards. OpenTelemetry (OTel) is an open observability standard, and Claude Code can stream per-request timing and usage events to it alongside a session. That sidecar logged 236 api_request events across the 20 sessions, so charts 16 to 18 show the burn-rate race, per-tool wall-clock budget, and streaming throughput from telemetry that was validated against the CLI ground truth.
latency
Wall-clock below means total elapsed real time - stopwatch time, not compute time.
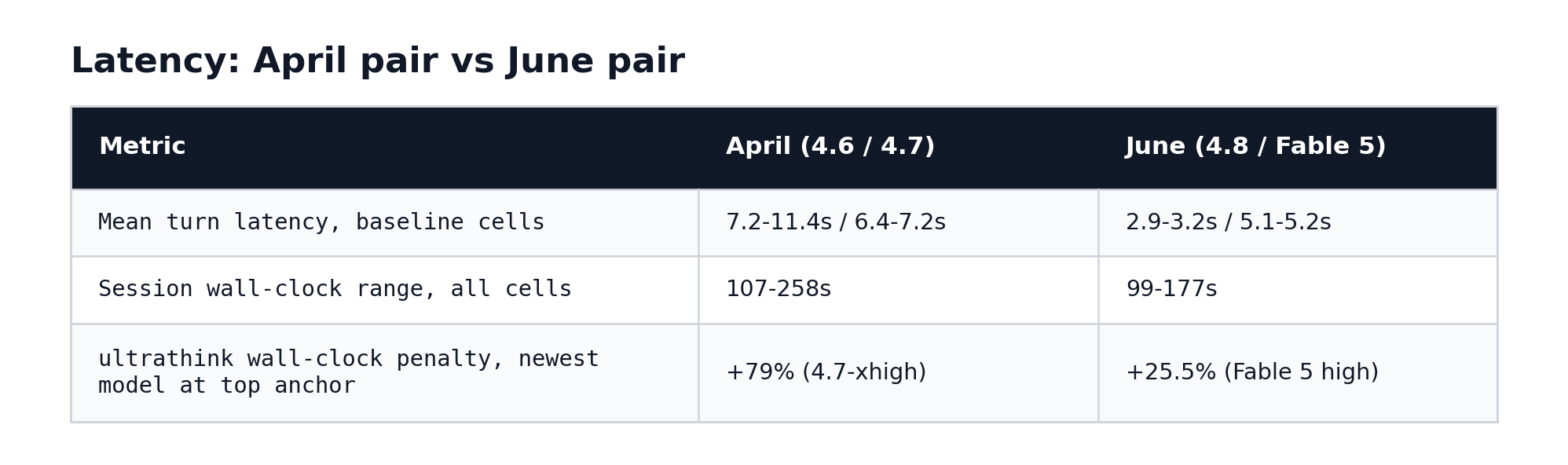
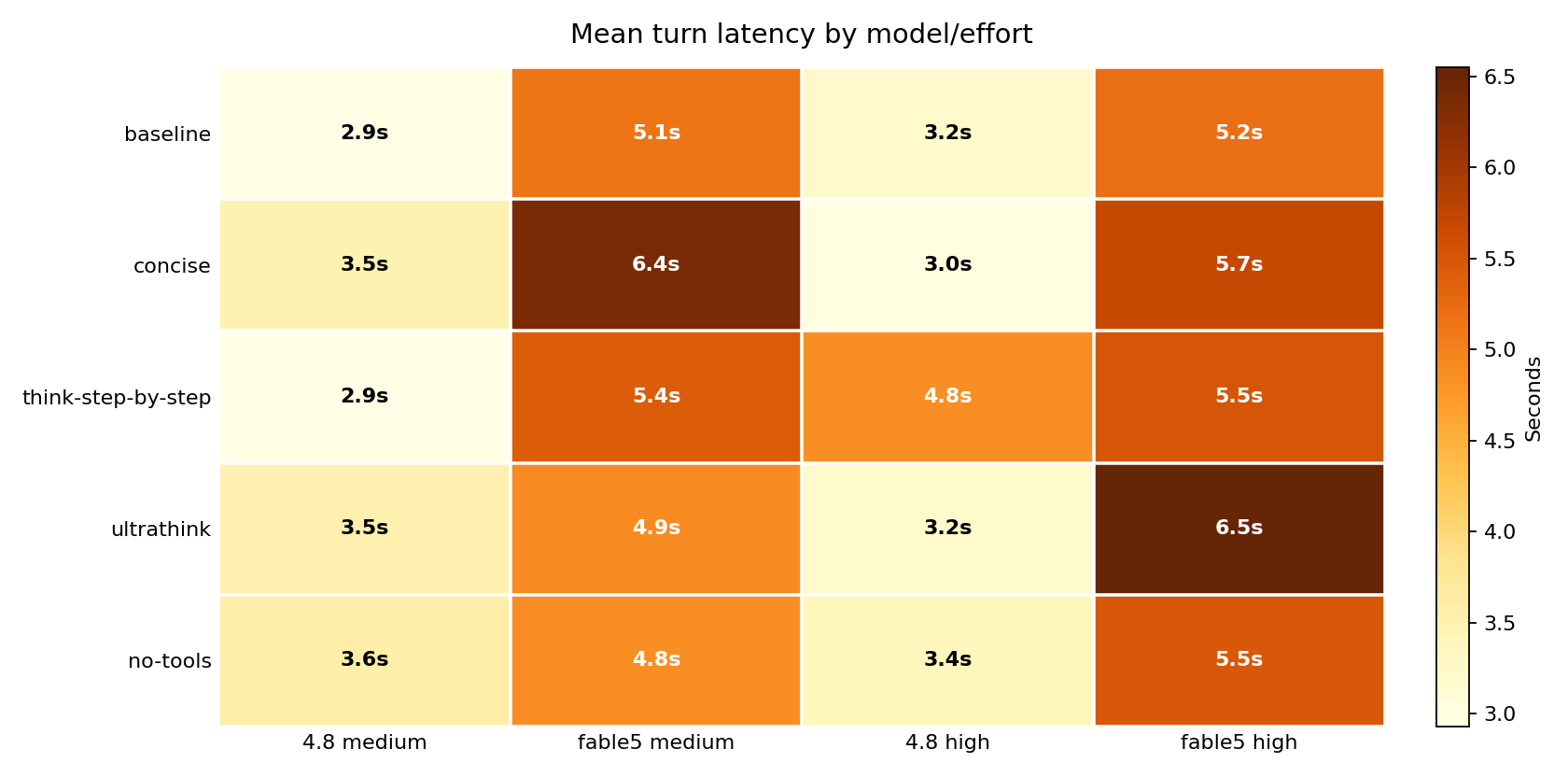
Plain English: From raw benchmark logged numbers, both June models for Opus 4.8 and Fable 5 are much faster than April’s pair of Opus 4.6 and Opus 4.7. The “ultrathink makes you wait” tax shrank from 79 percent to 25 percent on the newest model, and on Opus 4.8 high it disappeared entirely for 3.2s baseline vs 3.2s ultrathink. At medium, ultrathink stretches 4.8's turns from 2.9s to 3.5s - a ~21 percent per-turn wait.
Technical read: Opus 4.8’s mean turn latency spans 2.93 to 4.85 seconds across all 10 cells; Fable 5 spans 4.85 to 6.55. Compare April: Opus 4.6 ran 6.57 to 19.45 seconds per turn (its ultrathink cell at xhigh-anchor hit 19.45s mean and 258s wall-clock), Opus 4.7 ran 5.72 to 10.93. The worst June cell (Fable 5 ultrathink high, 177s wall-clock, +25.5 percent vs its baseline) would have been mid-pack in April. Fable 5’s latency profile has one rough edge: long time-to-first-token on heavy prose - its medium-baseline claudemd_summarise answer took 24 seconds before the first token.
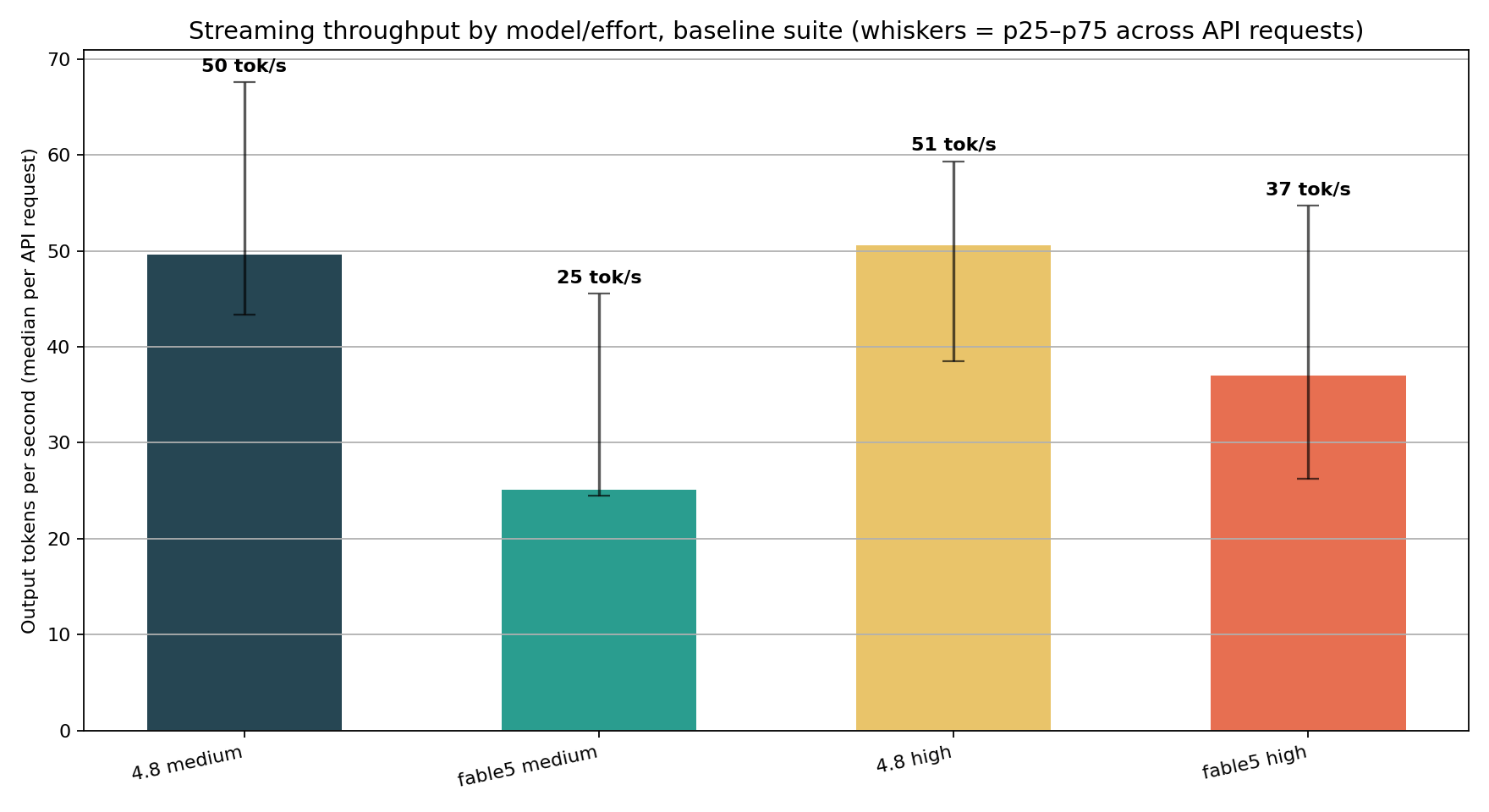
Plain English: per-request streaming speed tells the same story - the June Opus 4.8 and Fable 5 models aren’t just cheaper per token, they deliver tokens faster than April Opus 4.6 and Opus 4.7 models.
what I learned
The inversion is a property of the model generation, not of the wrapper. April’s lesson was “test your steering phrases per model”. That survived two model generations, but every specific finding moved: think-step-by-step went from inverted to universally costly, ultrathink went from a 4.7 problem to a Fable 5 problem, and concise developed a brand-new effort-dependent inversion on 4.8. A steering phrase tuned on the previous model is a guess on the next one.
Fix your benchmark before trusting its trend. The cold-cache bias inflated both April baselines by $0.46 to $0.63, which made no-tools look like a 60 percent lever when it was a 44 percent one - and hid that think-step-by-step was an 85 percent tax, not 22. The corrected trend across four models shows no-tools value shrinking generation over generation (45, 44, 23, 10 percent), which is a much more useful fact than the original headline.
Keep concise away from refactoring and content-constrained tasks. Two generations of models failed the refactoring prompt the same way under compression wrappers: the code survived, the required content around it got squeezed out. Concise steering is for open-ended questions, not for tasks where the answer must contain specific things.
Fable 5’s premium is the rate card, not verbosity - at high effort. At the high anchor Fable 5 consumed slightly fewer rate-adjusted token-dollars than Opus 4.8 for the same suite. If Fable 5 quality justifies 2x pricing for your task, its token discipline at high effort isn’t the problem. At medium, it is: 43 percent heavier rate-adjusted, with the spend concentrated on open-ended prose.
Run Fable 5 at high, not medium - for normal prompting. Medium cost more than high not just at baseline ($1.33 vs $1.14) but under concise and think-step-by-step too; only ultrathink and no-tools came in slightly cheaper at medium. Anthropic’s recommendation of high for Fable 5 matches what the data shows; there’s no economy rung hiding at medium unless you’re also suppressing tools.
Don’t bolt ultrathink onto Fable 5. +31 percent cost and +25.5 percent wall-clock at high effort, spread across nearly every prompt, for zero IFEval gain (8/9 both ways). On Opus 4.8 the same wrapper was free (-2.6 percent). This is the single most actionable per-model rule in the run.
Constraint personalities are stable enough to plan around. Opus 4.7 and 4.8 share the word-count overshoot. Fable 5 counts words perfectly but budget-fills character caps. If your pipeline has hard length limits measured in characters, 4.8’s the safer side; if they’re measured in words, Fable 5 is - and neither model’s thinking placement tells you which constraints it’ll actually honour.
What’s Next
The obvious follow-up is the recommended-vs-recommended run: Opus 4.8 at xhigh against Fable 5 at high, which is the asymmetric pairing Anthropic’s own guidance implies for coding work. This run’s symmetric high anchor slightly undersells 4.8. I also want to repeat the suite once Fable 5 gets its first point release, to see whether the ultrathink sensitivity is a launch-version quirk or a family trait - the 4.6-to-4.8 lineage suggests these fingerprints persist.
CTA
If you’re interested in practical AI building for web apps, developer workflows, and infrastructure, subscribe for future posts. You can also follow my shorter updates on Threads (@george_sl_liu) and Bluesky (@georgesl.bsky.social) or subscribe and follow along.