
Building an AI Image Creator Skill for Claude Code
ai-image-creator skill for LLM models

I needed project images for web apps and web sites I was developing. Logos, social media banners, product shots. The usual approach is to open ChatGPT, Google Gemini, Midjourney or DALL-E, generate something, download it, resize it manually, hope the style stays consistent across sizes. Repeat for every asset.
Instead, I built a Claude Code skill that generates images from the terminal and also via Claude Desktop MacOS app (see Claude Cowork example below). One command, any AI model, with transparent backgrounds, reference image editing, prompt engineering patterns, and composite banner generation built in. Every image on my Timezone Scheduler site was created this way without ever leaving my code editor.
This post walks through what the skill does, how it works under the hood, and why building image generation into a developer workflow changes how you think about visual assets.

What problem this solves
If you are a developer building web apps, you probably treat image assets as a separate workflow. You switch to a browser-based AI tool, type a prompt, download the result, maybe resize it with a separate tool, then move it into your project. Each image is a context switch.
The ai-image-creator skill eliminates that. It runs inside Claude Code, so you stay in your terminal the whole time. You describe what you want in natural language, Claude Code enhances your prompt using built-in patterns, picks the right model, and generates the image directly into your project directory. If you need multiple sizes for social media or ad banners, a separate composite mode handles that from a single config file.
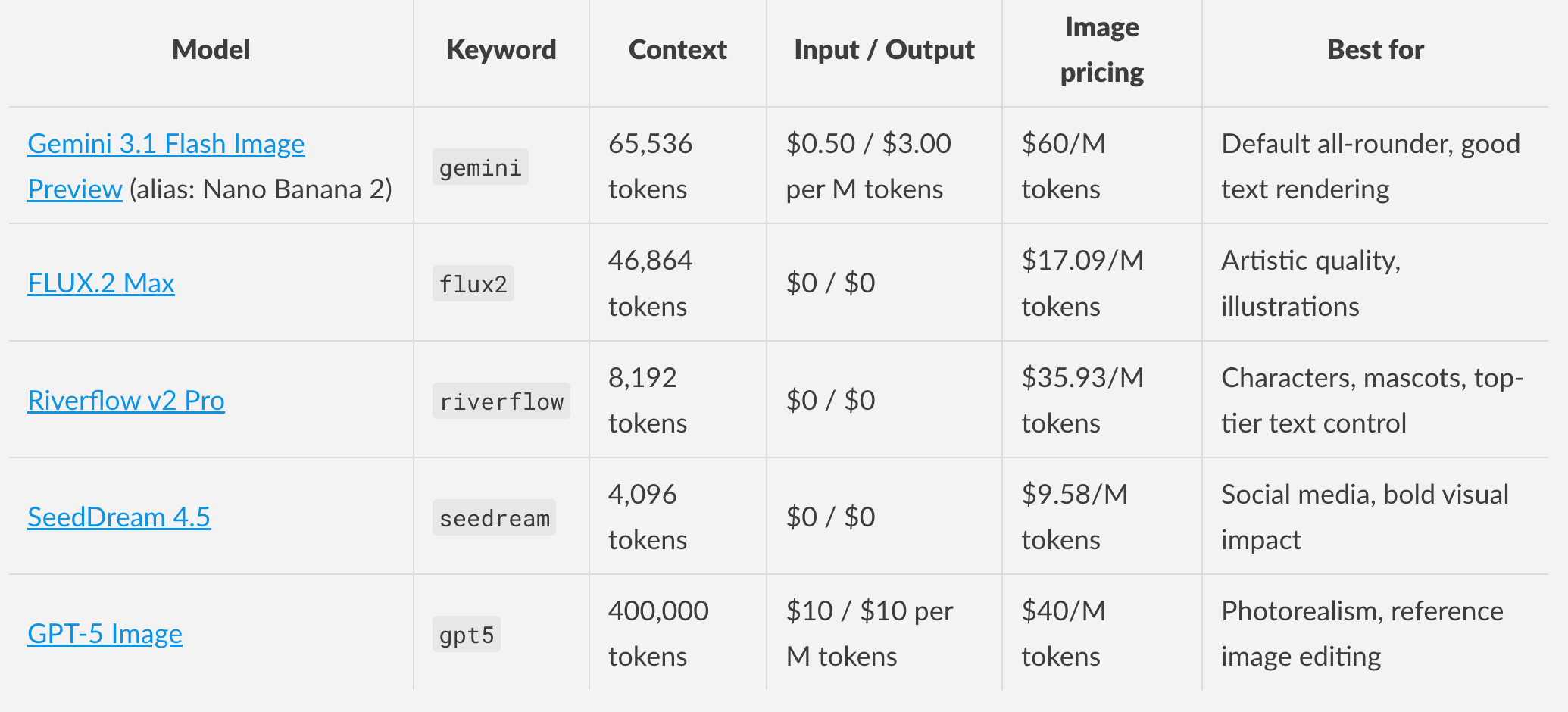
The skill supports five AI image models through OpenRouter’s API, all proxied through Cloudflare AI Gateway for monitoring and cost control:
Gemini 3.1 Flash Image Preview (Google Nano Banana 2)
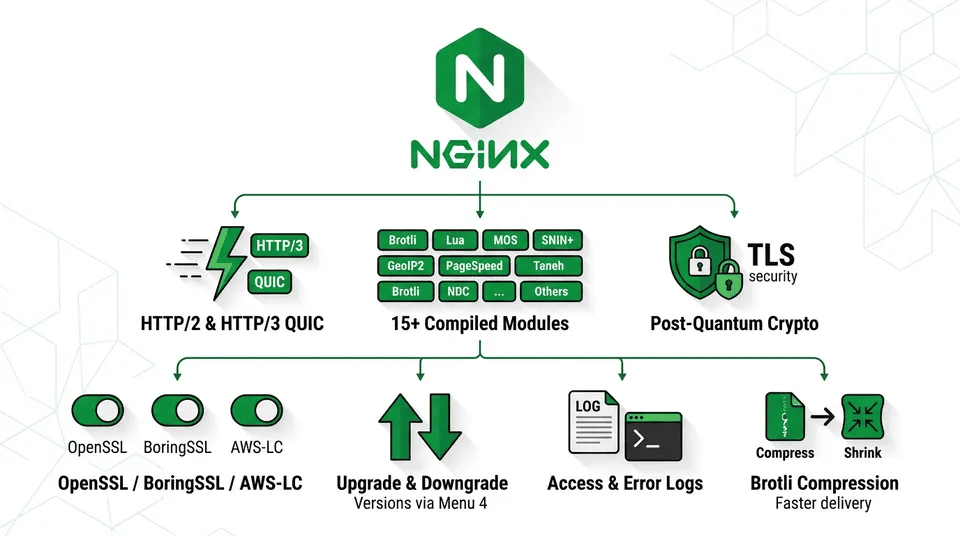
Example image created for my Centmin Mod site’s Nginx page. I asked Claude Code read each local copy of my sites’ pages and generate an image that accurately depicts the content conveyed on each page.
How SKILL.md uses progressive disclosure
Before getting into what the skill does, it is worth explaining how it is structured, because the design pattern is reusable for any complex Claude Code skill.
The SKILL.md file is the entry point. It uses progressive disclosure: only the instructions immediately needed for any given task are loaded into context. The bulk of the knowledge lives in separate reference files that are only read when a specific category is detected.
Here is how it works in practice. SKILL.md contains a routing table:
If the request mentions “product shot” or “product photo” → read
prompt-core.md+prompt-categories.mdsectionproduct_hero
When you ask for a product shot, Claude Code reads only those two files. If you ask for a social media graphic, it reads a different pair. If you ask for a simple image with a basic prompt, it skips the reference files entirely and generates directly.
The alternative would be loading all ~25,000 words of prompt engineering reference into every single request. That would consume a large portion of the context window even for trivial requests like “generate a blue circle.” Progressive disclosure keeps the skill lightweight for simple tasks and deep for complex ones.
The three reference files behind the routing:
prompt-core.md– foundational rules: narrative prompting, camera/lens specs, lighting setups, text rendering rules, model recommendationsprompt-categories.md– 11 category formulas with templates and complete example promptsprompt-platforms.md– social media ratios, IAB ad sizes, web dimensions, POD specs
A fourth file, composite-reference.md, is only loaded when composite banner mode is detected. The analyze mode has its own analyze-reference.md. The setup guide is in setup-guide.md. None of these are loaded unless the routing logic determines they are needed.
This pattern keeps skill files maintainable too. When I update the product_hero formula, I edit one section of one file. When I add a new model, I update one table in SKILL.md. No sprawling monolith to edit.
How it works
The skill is a Python script (~1,300 lines) that runs through uv (a fast Python runner). The core workflow is three steps:
Write or enhance a prompt. For simple requests, pass an inline prompt. For anything complex, write to a temp file. The skill includes prompt engineering reference files covering 11 categories (product hero shots, lifestyle photos, social media graphics, marketing banners, icons, illustrations, food photography, architecture, infographics, print-on-demand designs, and image analysis). Each category has a formula template with camera specs, lighting setups, and composition guidance.
Generate the image. The script calls OpenRouter’s API (or Google AI Studio directly), routing through Cloudflare AI Gateway when configured. You control aspect ratio, resolution, model selection, and output path.
Post-process if needed. Resize, convert formats, or generate transparent backgrounds using FFmpeg and ImageMagick pipelines.
A typical command looks like this:
uv run python generate-image.py \
-o "assets/hero-banner.png" \
-m gemini \
-a "16:9" \
-s "2K" \
-p "A flat-design globe icon with timezone band lines in blue and teal"This will generate a image at with an accompanying markdown file which contains the actual prompt the ai-image-creator skill used
ls -lAh
total 4696
-rw-r--r--@ 1 george staff 2.3M 5 Apr 02:12 hero-banner.png
-rw-r--r--@ 1 george staff 249B 5 Apr 02:12 hero-banner.prompt.md
# Prompt
- **Model:** google/gemini-3.1-flash-image-preview
- **Provider:** openrouter (gateway)
- **Aspect ratio:** 16:9
- **Image size:** 2K
- **Elapsed:** 38.5s
## Prompt Text
A flat-design globe icon with timezone band lines in blue and tealThe prompt engineering layer
This is where most of the value lives. The difference between a mediocre AI image and a professional one is almost entirely in the prompt. The skill includes three reference files totalling ~25,000 words of prompt patterns I refined through hundreds of generations.
Core principle: narrative over keywords. “A warm afternoon in a sunlit cafe with a steaming latte on a marble table” produces dramatically better results than “latte, cafe, warm, marble, afternoon, sunlit.” The reference files teach Claude Code to compose prompts as scene direction, not tag lists.
Camera language triggers photorealism. Including real camera specs (Sony A7R IV, 85mm macro at f/2.8) pushes models toward photorealistic output. The reference files map camera/lens/aperture combinations to specific use cases: 85mm macro for product shots, 100mm macro for food, 24mm tilt-shift for architecture, 35mm for lifestyle scenes.
Quality modifiers are wasted tokens. Words like “4K”, “ultra HD”, “masterpiece” are ignored by modern image models. The reference files focus on describing what you actually want instead of asking for generic quality.
Text rendering has specific rules. AI models can render text in images but need precise instructions. Always wrap text in quotation marks. Describe font style (“bold condensed sans-serif”), not font names (“Bebas Neue”). Specify placement, case, and how text integrates with the design. Following these rules gets 95%+ text accuracy.
Each of the 11 categories has a formula template. Here is the product hero pattern:
Create a [lighting] product photograph of [detailed product description] on/against [surface/background]. Shot with [camera] [lens] at [aperture]. [Lighting description]. [Composition notes]. [Mood/atmosphere].
Claude Code detects the category from your request and loads the matching pattern automatically. If you ask for “a product shot of headphones,” it reads the product_hero template and composes a detailed prompt with camera specs, lighting direction, surface material, and atmosphere. You still control what you want. The skill just makes sure the prompt is structured for the best possible output.

Transparent backgrounds without Photoshop
One feature I use constantly is transparent mode (-t). It generates images with transparent backgrounds using a three-step pipeline:
The prompt is augmented to place the subject on a solid green (#00FF00) screen
FFmpeg removes the green background and cleans up green fringe from edges
ImageMagick auto-crops the transparent padding
Gives you clean PNGs with alpha channels for icons, logos, mascots, sprites, and any asset that needs to sit on different backgrounds. No manual masking, no Photoshop.
uv run python generate-image.py \
-o "mascot.png" -t \
-p "A friendly robot mascot character in flat illustration style"
A friendly robot mascot character in flat illustration styleReference image editing
Multimodal models (Gemini and GPT-5) accept reference images alongside text prompts. This enables editing, style transfer, and guided generation:
# Edit an existing image
uv run python generate-image.py \
-o "edited.png" -r "photo.png" \
-p "Make the background white"
# Style transfer with multiple references
uv run python generate-image.py \
-o "combined.png" -r "style.png" -r "content.png" \
-p "Apply the style of the first image to the second"
When you provide a reference, the prompt should describe what to change, not the entire scene. The model sees the original and needs edits, not a full new description. This is useful for iterating on designs: generate a base image, then refine it through successive edits without starting over.
Composite banners: consistent branding at every size
The second script in the skill (composite-banners.py) solves a different problem. When you have an existing logo and need it rendered consistently across 15 different banner sizes (social media covers, IAB ad formats, email headers, OG images), AI generation is the wrong tool. Each generation would produce slightly different styling.
Composite mode uses ImageMagick for offline compositing. No API calls, no network required. You define your brand in a JSON config (logo path, brand name, tagline, colors, font preferences) and specify which banner sizes you need. One command generates all of them with pixel-perfect consistency.
# Initialize a config
uv run python composite-banners.py --init
# Generate all banners
uv run python composite-banners.py \
-c banner-config.json -o ./banners/The config supports horizontal, horizontal-compact, and centered layouts. It includes presets for IAB standard ad sizes (leaderboard, billboard, medium rectangle, skyscraper), social media covers (Twitter, LinkedIn, Facebook, YouTube), and web assets (hero banners, OG images, email headers, favicons).
The most powerful workflow combines both scripts. Use generate-image.py to AI-create a hero background or textured pattern, then use composite-banners.py to overlay your logo and text onto that background at all standard sizes. Creative AI visuals plus pixel-perfect logo consistency.
Image analysis
The skill also works in reverse. Instead of generating images, you can analyze existing ones using multimodal AI vision:
uv run python generate-image.py \
--analyze -r "assets/cafe-latte.png" \
-p "Describe the subject, style, colors, and composition"This returns a JSON response with the model’s analysis. Useful for generating alt text, comparing before/after versions, or understanding what a competitor’s visual assets are doing well. You can analyze multiple images together for comparison.
Claude Code Opus 4.6 response:
Subject: A first-person POV inside a cozy Parisian cafe — steaming latte with latte art on a marble table, two books (including “The Hidden Life of Trees” with tortoise-shell glasses resting on top), a hand holding an open book, and a large window overlooking a bustling street with trees and passersby.
Style: Digital photograph with a filmic quality — visible grain, shallow depth of field, candid/documentary feel.
Colors: Warm, natural palette — rich browns from wood and the cup, greens from potted plants and outdoor trees, stone-beige masonry, warm gold/yellow from overhead lighting, faded whites from furniture.
Composition: Two-part split (indoor/outdoor) separated by the window frame. Shallow depth of field keeps the foreground sharp (hand, books, cup) while the background softens. Window panes and wood trim act as leading lines toward the center. Asymmetrical but balanced table arrangement.
An example of using ai-image-creator skill —analyze to deconstruct an image into JSON structured data with Google Nano Banana 2 and compare it to Claude Opus 4.6’s own native visual image support. Google Nano Banana 2 picked up more details than Clause Opus 4.6 with my Claude Cowork desktop chat session.

Now that Claude understands the reference images style and composition, I can assign this style a name Substack Comic Style - for this Substack’s creative images that I create for each of my Substack article posts. You’ll need to subscribe to my Substack to find out what article these generated images belong to 😉

Cost tracking
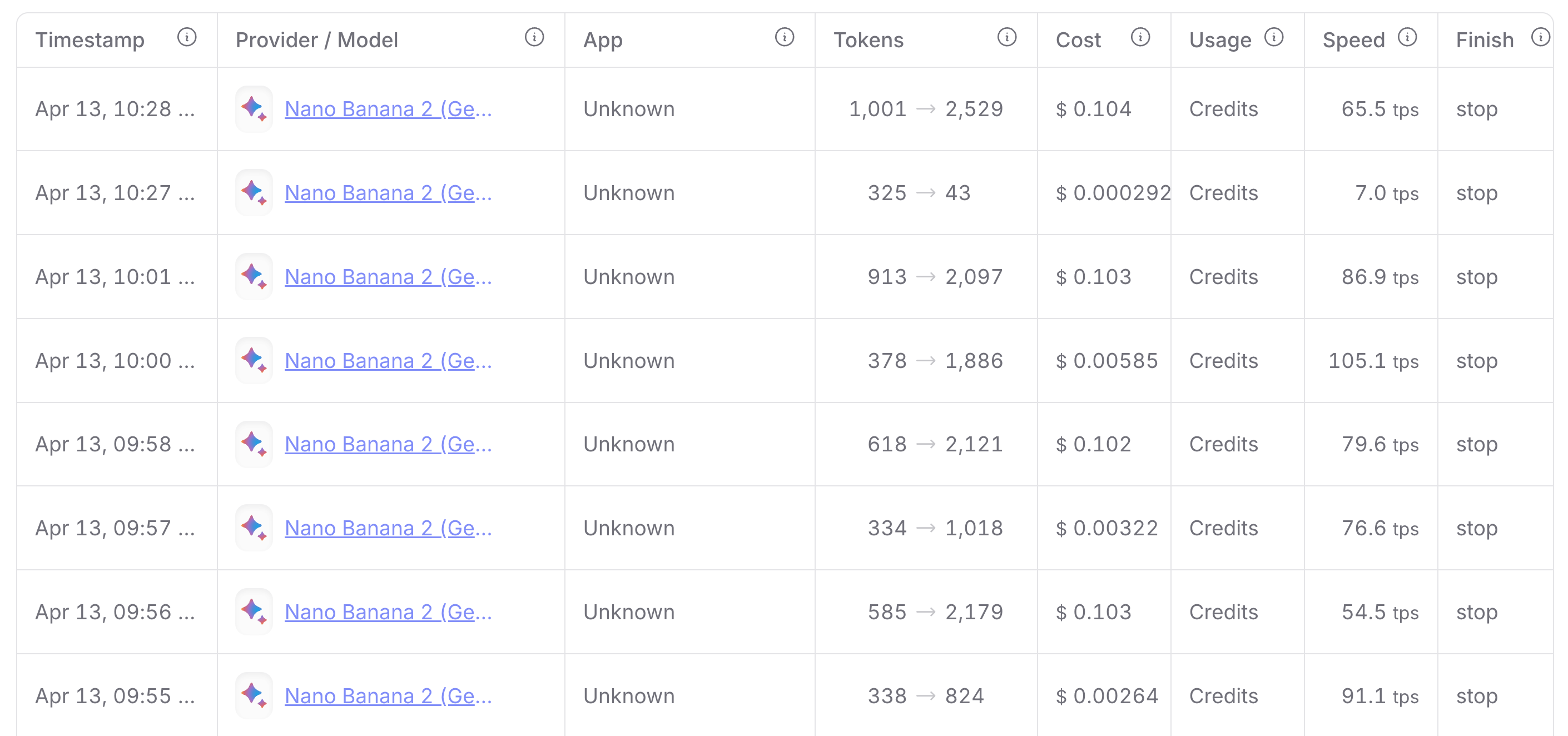
Every generation is logged to a local .ai-image-creator/costs.json file in your project directory. Running --costs shows per-model breakdown: generation count, total tokens, elapsed time, and recent entries. No API keys or credentials are ever stored, just usage metadata.
This matters when you are generating dozens of images for a project. You can see exactly which models you are using, how much each generation costs, and where your budget is going.
The Cloudflare AI Gateway layer
All API calls can be routed through Cloudflare AI Gateway using BYOK (Bring Your Own Key). Your API keys are stored securely in Cloudflare’s dashboard, never sent in request headers from your machine. The gateway provides unified logging across all models and providers, cost monitoring at the account level, rate limiting to prevent accidental overspend, and automatic fallback to direct API calls if the gateway is unavailable.
This is the same gateway pattern I use for other AI integrations. Once you have it set up, every AI API call in every project goes through the same monitoring and cost control layer.
One practical note on credentials: the script supports a .env file at scripts/.env inside the skill folder. This matters for desktop AI tools like Cowork, which run in sandboxed shells that do not inherit your ~/.zshrc exports. Populate the .env with your gateway variables, zip the skill folder, and install it in Cowork -- the script loads credentials automatically using only stdlib (no extra dependencies) and never overwrites keys already set in the environment. Running from a regular terminal with shell exports works the same as before.
Using the skill in other AI coding tools
The skill format follows the open Agent Skills standard, which means it works in more than just Claude Code. The same ai-image-creator/ directory can be transplanted into Codex CLI, Gemini CLI, Kilo Code, and OpenCode with minimal changes. Each tool has its own discovery path:
Codex CLI – Copy the skill folder to
~/.codex/skills/for global availability, or to.agents/skills/at the project root for repo-scoped use.Gemini CLI – Place the skill inside
~/.gemini/extensions/<extension-name>/skills/for a user-level extension, or in.agents/skills/in your workspace.Kilo Code – Drop it into
.kilocode/skills/at the project root, or add the path viaskills.pathsin yourkilo.jsoncconfig for global availability across projects.OpenCode – Global skills go in
~/.config/opencode/skills/. Project-scoped skills go in.opencode/skills/and take higher priority.
The SKILL.md frontmatter (name, description, allowed-tools, compatibility) is read by all of these tools to discover and describe the skill. The generate-image.py script itself is tool-agnostic: it runs via uv run python, which works the same regardless of which AI coding harness invokes it.
One thing to check across tools: the ${CLAUDE_SKILL_DIR} variable used in SKILL.md to reference script paths. Claude Code expands this automatically. Other tools may not. If a tool does not expand ${CLAUDE_SKILL_DIR}, replace it with an absolute path or a $(dirname "$0")-style resolution in the script invocations.
What I learned building this
Prompt structure matters more than model choice. Switching from a keyword-style prompt to a narrative prompt with camera specs improved output quality more than switching between models. The reference files encode this knowledge so you do not have to rediscover it for each generation.
Transparent backgrounds are harder than they look. My first attempt used simple color replacement, which left green fringe artifacts around edges. The FFmpeg chroma key pipeline with edge cleanup handles this properly, but it took several iterations to get clean results on complex shapes like hair or translucent materials.
Composite mode saved the most time. Generating 15 banner sizes individually with AI would take 15 API calls, 15 different results, and manual checking for brand consistency. Composite mode does it in one local operation with zero API cost and guaranteed consistency.
Cost tracking changes behavior. Once you can see per-generation costs, you start making smarter choices about which model to use for which task. Gemini is cheap and versatile for most web assets. FLUX.2 is better for artistic work but costs more. Having the data makes the trade-off explicit.
What did not work
Film stock prompts are hit or miss. The reference files include film stock aesthetics (“Shot on Kodak Portra 400” for warm skin tones, “Shot on CineStill 800T” for cinematic tungsten tones). Some models respond well to these, others ignore them entirely. I keep them in the reference because when they work, the aesthetic shorthand saves a lot of descriptive text.
Text rendering still fails on long strings. Even with the seven-rule system (quotation marks, font style not name, explicit case, short text), anything beyond 5-6 words becomes unreliable depending on the model. Google Gemini 3.1 Image Flash / Google Nano Banana 2 is much better at text rendering though.
Google AI Studio free tier does not support image generation for Google Gemini 3.1 Image Flash / Google Nano Banana 2. The quota is zero for image generation unless you enable billing on the linked Google Cloud project. I documented this in the setup guide after debugging a cryptic 429 RESOURCE_EXHAUSTED error. OpenRouter’s pay-as-you-go model is simpler for most users.
How to use it
The skill is open source, bundled in my Claude Code starter template repository at .claude/skills/ai-image-creator/. To use it in your own Claude Code projects:
Copy the
ai-image-creator/folder to your project’s.claude/skills/directoryAdd permission entries to
.claude/settings.local.jsonSet your API keys. There are two ways depending on how you run the skill: Terminal / Claude Code CLI: Export variables in your shell profile (
~/.zshrcor~/.bashrc):
bash
export AI_IMG_CREATOR_CF_ACCOUNT_ID="your-account-id"
export AI_IMG_CREATOR_CF_GATEWAY_ID="your-gateway-name"
export AI_IMG_CREATOR_CF_TOKEN="your-gateway-token"
# Or for direct OpenRouter access without a gateway:
export AI_IMG_CREATOR_OPENROUTER_KEY="sk-or-..."Claude Cowork (desktop app): Cowork runs in a sandboxed shell that does not inherit your shell profile. Create a .env file at scripts/.env inside the skill folder:
AI_IMG_CREATOR_CF_ACCOUNT_ID=your-account-id
AI_IMG_CREATOR_CF_GATEWAY_ID=your-gateway-name
AI_IMG_CREATOR_CF_TOKEN=your-gateway-tokenThen zip the entire ai-image-creator/ folder (with the populated .env inside) and install it as a skill in Cowork. The script loads the .env automatically on startup. Shell exports take precedence over the .env if both are present.
Then Ask Claude Code to generate an image.
The setup guide in references/setup-guide.md walks through every step, including Cloudflare AI Gateway configuration and BYOK provider key setup.
An example of ai-image-creator skill in action within Claude Cowork desktop app for MacOS with a Claude Cowork project.

Claude Desktop MacOS app uploaded ai-image-creator skill:
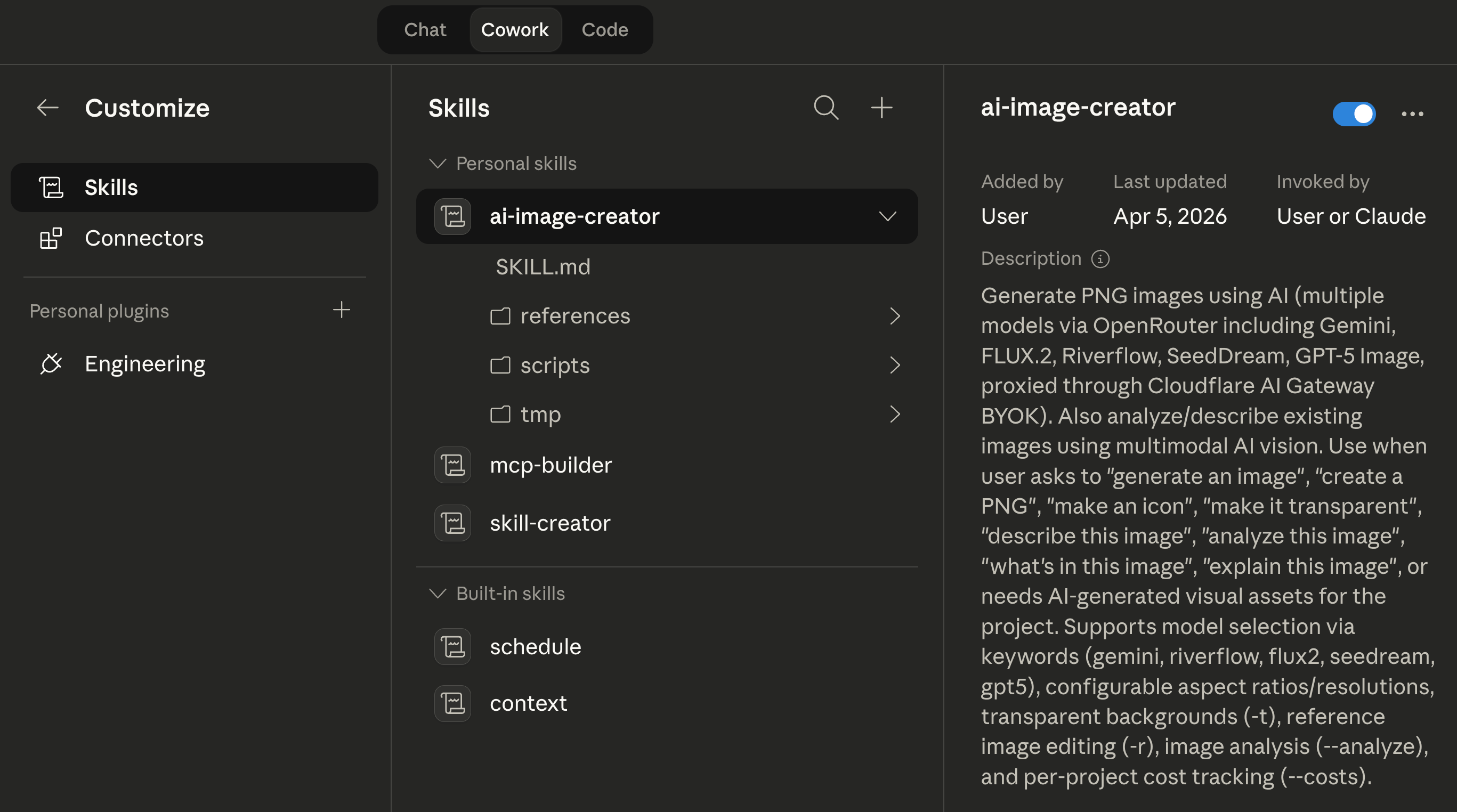
Now with Claude Cowork desktop app paired with my AI Image Creator skill, I am just prompting for image creation and editing. I updated my Substack logo using the skill settling on one of the three generated images.

The costs for using AI image creator skill with Google Nano Banana 2 - literally pennies 😎
Claude Opus 4.7 vs Google Nano Banana 2 Vision Capabilities
Claude Opus 4.7 was released and has improved vision capabilities compared to Claude Opus 4.6. So tested Claude Opus 4.7 vs Google 3.1 Image Fast/Google Nano Banana 2 via my ai-image-creator skill’s —analyze flag.
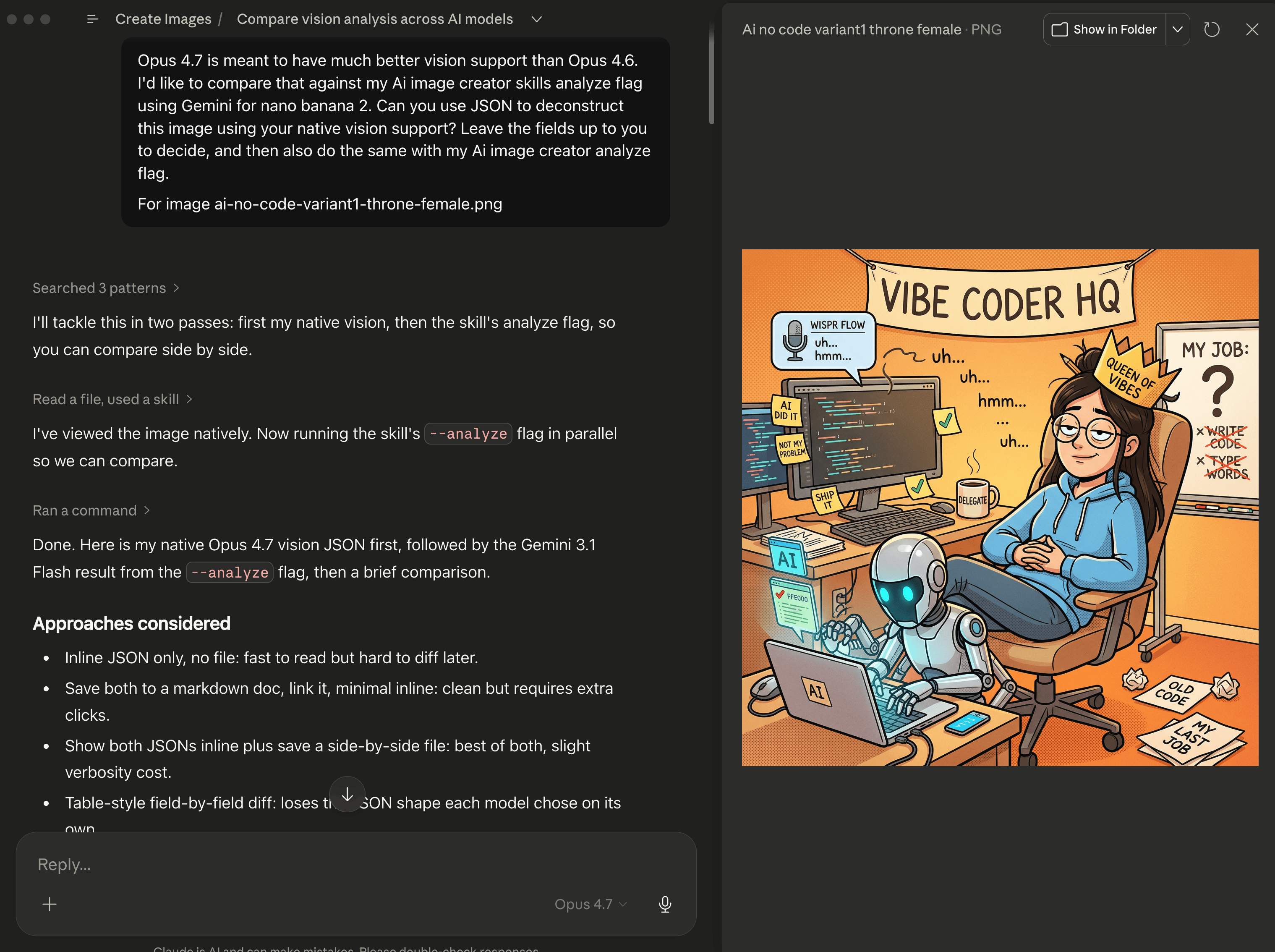
Definitely Claude Opus 4.7 has improved compared to Claude Opus 4.6. When compared to Google Nano Banana 2, it’s on par it would seem.
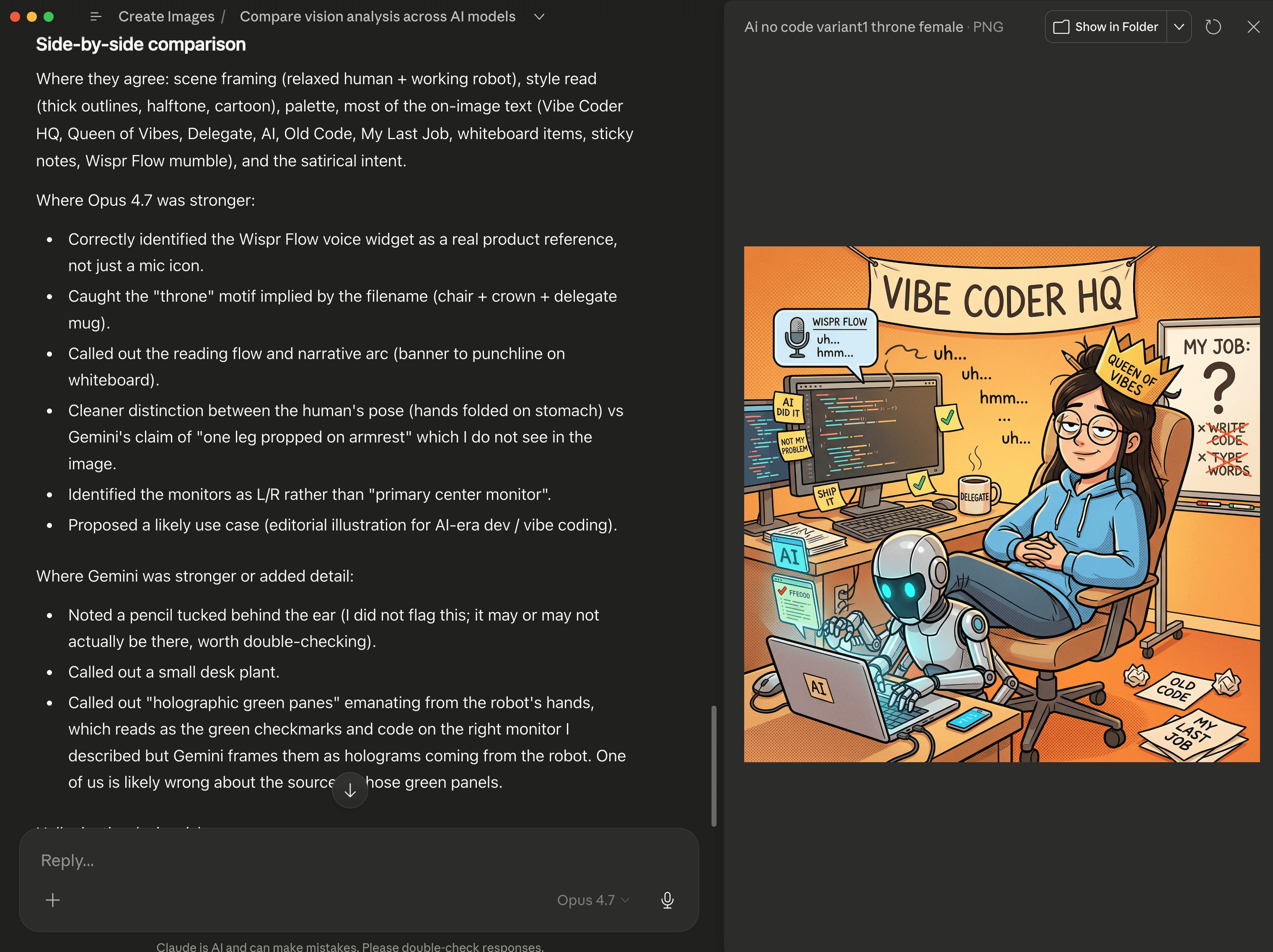
Opus 4.7 native vision JSON
{
"image_type": "single-panel editorial webcomic illustration",
"title_element": {
"text": "VIBE CODER HQ",
"format": "hanging cloth banner, upper center, black serif caps on cream"
},
"art_style": {
"line": "uniform thick black ink outlines",
"shading": "flat fills with light cross-hatching on chair and clothing",
"background_treatment": "orange-peach field with faint halftone/dot texture",
"genre": "warm editorial caricature, webcomic aesthetic"
},
"palette": {
"dominant": ["peach-orange", "powder blue hoodie", "tan-amber office chair"],
"accents": ["gold crown", "cyan robot eye-glow", "green code on monitor", "yellow sticky notes"],
"neutrals": ["black outlines", "cream banner", "white whiteboard"]
},
"characters": [
{
"role": "human protagonist",
"position": "right of center, seated in office chair",
"gender_read": "female-coded",
"hair": "long, dark brown, parted middle",
"face": "round glasses, half-closed smug eyes, small closed-mouth smirk",
"wardrobe": "light blue pullover hoodie, dark denim jeans",
"headwear": {"item": "folded paper crown", "label": "QUEEN OF VIBES", "color": "gold/yellow"},
"pose": "slouched back, hands folded over stomach, legs relaxed, zero engagement with the keyboard",
"affect": "contented, uninvolved, taking credit"
},
{
"role": "AI assistant",
"form": "humanoid desk robot",
"materials": "matte white and silver plating, exposed cable joints",
"eyes": "horizontal cyan light-slits",
"activity": "hunched over laptop, fingers on keyboard, visibly doing the actual work",
"position": "lower left, at the desk"
}
],
"setting": {
"location": "home office / bedroom workstation",
"wall": "orange-peach with subtle pattern",
"furniture": ["L-shaped desk with dual monitors", "tan rolling office chair", "mobile whiteboard easel at right"]
},
"props": {
"desk": [
{"item": "left monitor", "content": "lines of code, dark theme, colorful syntax"},
{"item": "right monitor", "content": "more code, green checkmarks"},
{"item": "laptop", "label": "AI", "user": "robot"},
{"item": "smartphone", "location": "front edge of desk"},
{"item": "coffee mug", "label": "DELEGATE", "detail": "wisps of steam"},
{"item": "stack of papers", "label": "AI"},
{"item": "keyboard and mouse"}
],
"whiteboard": {"heading": "MY JOB:", "question_mark": "large ?", "crossed_out_items": ["WRITE CODE", "TYPE WORDS"]},
"floor": [
{"item": "crumpled paper", "label": "OLD CODE"},
{"item": "paper sheet", "label": "MY LAST JOB"}
]
},
"text_and_ui_overlays": {
"voice_widget": {"app_name": "WISPR FLOW", "icon": "microphone", "transcript_showing": "uh... hmm...", "style": "rounded rectangle speech bubble, left side"},
"sticky_notes": [
{"text": "AI DID IT", "mark": "checkmark", "color": "yellow"},
{"text": "NOT MY PROBLEM", "color": "yellow"},
{"text": "SHIP IT", "color": "yellow"}
],
"floating_mumbles_above_human": ["uh...", "uh...", "hmm...", "uh..."]
},
"composition": {
"layout": "horizontal 3-zone: code workstation (L), relaxed human (center-R), outcome whiteboard (R)",
"focal_contrast": "robot actively typing vs human visibly idle",
"reading_flow": "banner -> mumbles -> human -> robot -> whiteboard punchline",
"negative_space": "minimal, dense with labeled props"
},
"mood": "wry, satirical, affectionate ribbing",
"narrative_reading": "AI coding agents have reduced the human's role to ambient vibing; she still wears the crown while the robot ships the code.",
"likely_use_case": "social post or article illustration about AI-era developers, vibe coding, Wispr Flow voice tools, or delegating to agents",
"notable_signifiers": [
"Wispr Flow branded voice bubble indicates actual product reference",
"Chair + crown + delegate mug form a 'throne' motif matching the filename",
"Crumpled 'OLD CODE' and 'MY LAST JOB' imply displaced labor"
]
}Gemini 3.1 Flash via ai-image-creator --analyze JSON
{
"sceneDescription": {
"overall": "A witty and satirical cartoon illustration depicting a person (presumably the 'Vibe Coder') relaxing while a functional robot handles all the technical work within an office called 'Vibe Coder HQ'.",
"style": "Modern cartoon illustration with thick outlines, halftone dots (screentone texture), clean flat and textured colors.",
"mood_tone": "Humorous, satirical, playful, ironic, relaxed, technologically advanced."
},
"setting_environment": {
"location": "Office labeled 'Vibe Coder HQ'. Walls orange-peach with subtle patterned texture.",
"details": "Desk setup, office chair, whiteboard on an easel, scattered items."
},
"characters": {
"person": {
"appearance": "Young person, possibly female, long dark hair, glasses.",
"accessories": "Gold paper crown 'QUEEN OF VIBES', pencil behind ear.",
"clothing": "Light blue hoodie, dark pants.",
"pose": "Relaxed in amber chair, eyes half-closed, hands clasped, one leg on armrest.",
"expression": "Content, smug, comfortable."
},
"robot": {
"appearance": "Humanoid silver/white robot with blue glowing eyes.",
"pose": "Sitting on floor, hands on laptop keyboard, blue lines/data going to holographic screens.",
"details": "Laptop labeled 'AI'."
}
},
"objects_props": {
"desk_setup": {
"monitors": "Two large desktop monitors, sticky notes attached.",
"mug": "Steaming mug labeled 'DELEGATE'.",
"plant": "Small green desk plant.",
"mic": "Microphone icon in speech bubble."
},
"whiteboard": "Whiteboard on easel with handwritten text.",
"floor": "Crumpled paper plus readable papers.",
"holographic_screens": "Two holographic green-glowing panes near robot.",
"miscellaneous": "Smartphone, adapter/wires."
},
"visibleText": {
"banner": "Vibe Coder HQ",
"whiteboard": {"title": "MY JOB:", "question": "?", "crossed": ["WRITE CODE", "TYPE WORDS"]},
"sticky_notes": ["AI DID IT", "NOT MY PROBLEM", "SHIP IT"],
"speech_bubble": {"app": "WISPR FLOW", "body": "uh... hmm..."},
"crown": "QUEEN OF VIBES",
"mug": "DELEGATE",
"laptop": "AI",
"floating_thoughts": ["uh...", "uh...", "hmm...", "...uh..."],
"floor_papers": ["OLD CODE", "MY LAST JOB"]
},
"colorPalette": {
"dominant": ["Orange-Peach", "Blue", "Brown/Amber", "Silver/Gray"],
"accent": ["Yellow", "Green", "White/Black"]
},
"composition": {
"center": "Desk, robot, person in chair.",
"focalPoint": "Robot's active hands vs person's relaxed posture.",
"framing": "Tight composition anchored by banner above and papers below."
},
"symbolism_narrative": [
"'Queen of Vibes' and relaxation suggest taking credit for AI labor.",
"'DELEGATE' mug is literal.",
"Sticky notes mock abdication of responsibility.",
"'OLD CODE' and 'MY LAST JOB' suggest automated role displacement.",
"Parody of modern software engineering with AI."
]
}Agreements: scene framing, style, palette, on-image text, satirical intent.
Opus 4.7 advantages:
Caught Wispr Flow as a real product reference.
Caught the ‘throne’ motif (matching filename).
Described narrative reading flow and likely use case.
More accurate pose description (hands folded on stomach, not leg on armrest).
Cleaner monitor layout (L/R).
Gemini advantages:
Caught pencil behind ear and desk plant. (False claim my Opus 4.7 evaluating)
Slightly more verbose prose in symbolism section.
Gemini hallucinations:
“Glowing blue lines emanating from fingertips onto holographic screens” -- the robot is just typing on a laptop.
“One leg propped on armrest” -- not visible.
Framed the right monitor’s code + checkmarks as “green holographic panes”.
Cost/latency: Gemini call 19.6s via gateway, logged to project cost file. Opus native vision was one Read, no extra spend.
Net: Opus 4.7 produced a more faithful and more semantically useful deconstruction with fewer hallucinations on this specific image.
What’s next
I am working on expanding model support as new image generation models land on OpenRouter. I am also exploring batch generation workflows where the skill generates all visual assets for a web project (favicon, OG image, social banners, app icons) from a single brand brief.
If you are building with Claude Code and want to see how custom skills extend what it can do, this is a concrete example.
I am also working on my video generation skill, AI Video Creator for text to video and image to video generation using KIE AI API - it is the cheapest video generation provider I have found that provides ByteDance Seedance 2.0, Kling 3.0, and Wan 2.7 and other bleeding edge video generation models on a PAYG basis. Subscribe for when those articles drop.
If you’re interested in practical AI building for web apps, developer workflows, and infrastructure, subscribe for future posts. You can also follow my shorter updates on Threads (@george_sl_liu) and Bluesky (@georgesl.bsky.social) or subscribe and follow along.